Introduction
Inference is key when using AI and models are only as useful as their ability to deliver fast, cost-effective, and scalable inference. It is the inference process that allows to make decisions using large amounts of data. But scaling this up has proven to be difficult because of the high need for resources.
Some of the main challenges when it comes to scaling up inference are:
-
Infrastructure cost.
-
Operational complexities.
-
Deployment constraints that make inference difficul across hybrid environments.
Because of the exponential growth of the capability and size of the models, more and more organizations want an efficient and standardized way to deploy their own, private AI solutions across environments and using several types of accelerators.
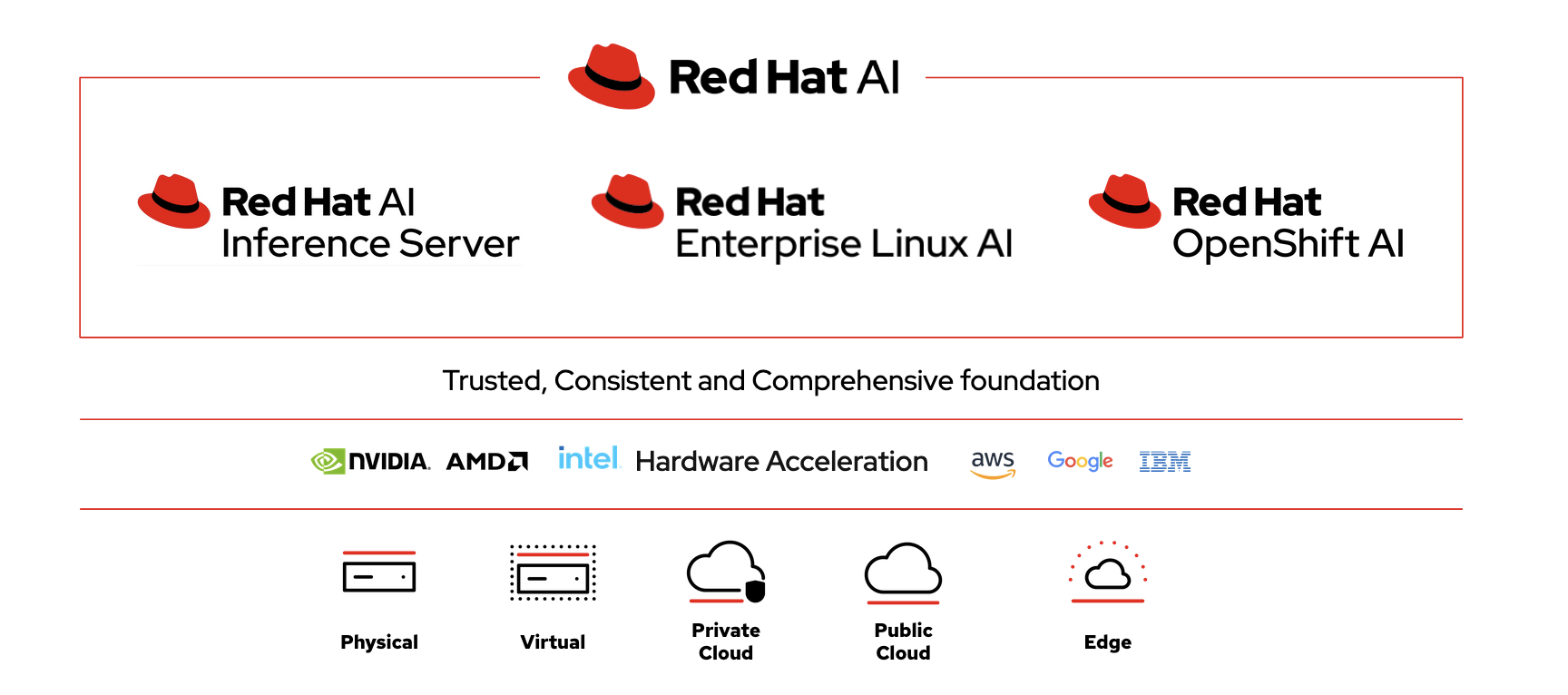
Red Hat AI Inference Server is a perfect solution because of its features:
-
Fast.
-
Cost-effective.
-
Performance.
-
It can serve most generative AI models.
-
It can use most AI accelerators.
-
It can be used on-premises as well as in public, private or hybrid cloud.
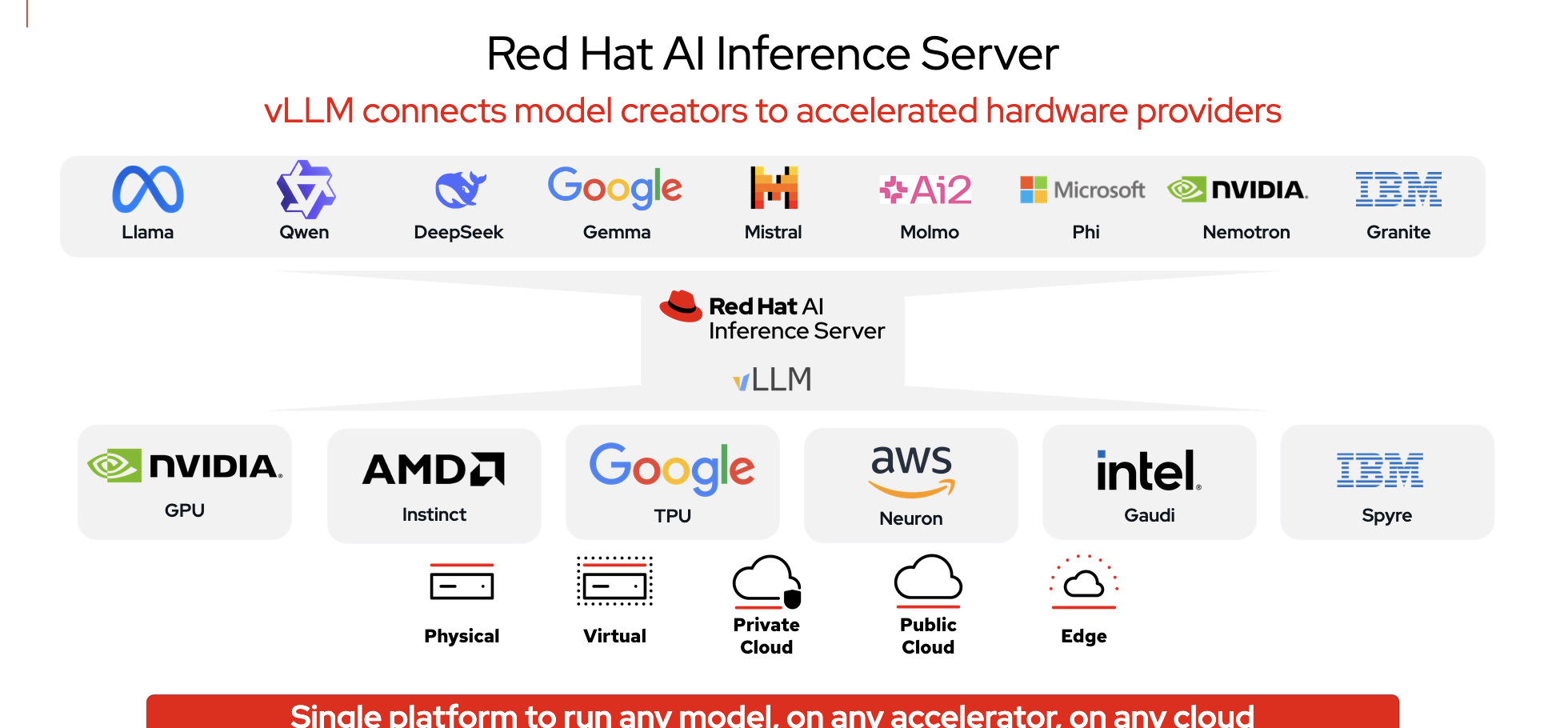
AI Inference Server is part of the overall Red Hat AI Platform. It has an enterprise-grade version of vLLM at its core. vLLM is an open-source library specifically designed to make inference and serve large language models (LLMs) significantly faster and being more memory-efficient than other solutions.
The other main component of Red Hat AI Inference Server is the LLM Compressor to reduce compute requirements and costs, while preserving model accuracy. This means faster and cheaper deployments.
Red Hat AI offers a repository of validated and optimized third-party models on Hugging Face. Ready-to-use and running efficiently on vLLM, these models provide organizations with faster time-to-value, promote consistency across teams, and enhance flexibility in choosing the best fit for their use cases. Validated models are third-party models that have been assessed for performance on vLLM and across a range of hardware using inference benchmarks and accuracy evaluations. Optimized models are third-party models that have been compressed for speed and efficiency, with the goal of improving performance while maintaining accuracy.