Module 2: Llama Stack Inference Basics
Welcome to the second module of our Llama Stack hands-on lab! Having set up your Llama Stack server, you’re now ready to dive into the core capabilities of interacting with Large Language Models (LLMs) using the Llama Stack client. This module introduces the fundamental concepts of making chat completion requests and working with structured data responses.
By the end of this module, you will be able to:
-
Initialize the Llama Stack client to connect to your running server.
-
Send simple chat prompts to an LLM and receive text responses.
-
Utilize structured response formats to extract specific information from LLM outputs programmatically.
Ready to see how easy it is to start building with Llama Stack?
Using Jupyter Lab
This module also marks a transition: from this point forward, all technical instructions, code examples, and detailed explanations for the lab exercises will be presented within Jupyter Notebooks.
Take a few moments to familiarize yourself with the JupyterLab interface. JupyterLab is a web-based interactive development environment. We’ll be using Jupyter Notebooks (.ipynb files) within it. Notebooks are documents that can contain both runnable Python code (in "code cells") and explanatory text, images, and links (in "markdown cells"). This format is excellent for learning and experimentation.
This interactive demo is recommended, a 60-second useful, short, introduction to JupyterLab for new users.
Please switch your focus to the "JupyterLab" tab, typically located to the right in your lab interface. You can adjust the width of this panel by dragging the divider if you need more space. Once in the JupyterLab tab, locate and open the notebook for this module: 02_Lllamastack_Inference_Basics.ipynb. Follow the steps within the notebook to explore these basic inference capabilities hands-on! All further instructions for this section will be found inside that notebook.
Reference material:
To help visualize the flow of information when interacting with Llama Stack, let’s look at a couple of simple diagrams. These illustrate how your code, the Llama Stack client, the server, and the LLM model work together.
First, here is the basic flow for a standard chat completion request:
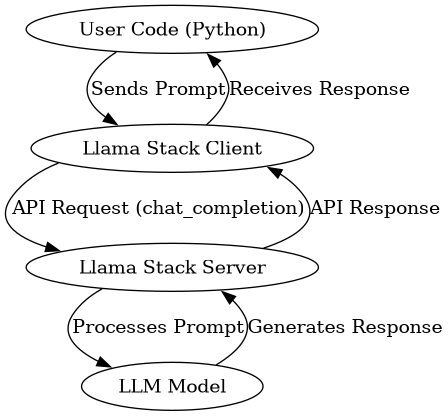
This diagram shows the request originating from your Python code, traveling through the Llama Stack client and server to the LLM, and the response following the path back. This highlights the role of the Llama Stack components in mediating the interaction with the AI model.
Now, let’s consider the flow when you request structured data using the response_format parameter:
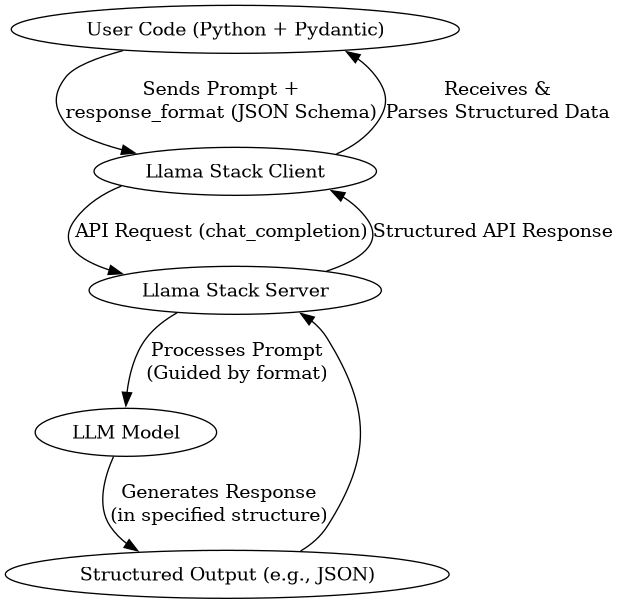
As you can see, the core flow is similar, but we’ve added the concept of the response_format guiding the LLM’s output. The diagram also emphasizes that the response returning contains structured data (like JSON), which your code (potentially using tools like Pydantic) can easily work with programmatically.
These visuals should help reinforce the concepts as you work through the code examples in the notebook.