LB 2645: An Agentic AI DevOps Assistant: Augmenting Incident Response
Welcome to the Agentic AIOps Assistant workshop!
|
Your login credentials
Username: These credentials work for every console in this lab:
|
Your role and mission
You’re a senior Site Reliability Engineer (SRE) at Meridian Financial, a UK-based financial services firm operating hybrid infrastructure across 140 on-premise RHEL VMs and three OpenShift 4 clusters.
Your team runs 600+ Ansible Automation Platform jobs per week — provisioning, patching, compliance scanning, and configuration drift correction. When jobs fail, a ticket lands automatically in Kira (Meridian’s AI-assisted ticketing system built on your internal tooling) and a notification fires in RocketChat.
This week, your manager pulled you aside: "The regulator flagged three SLA breaches in Q1. Each one traced back to a failed Ansible job that sat unactioned too long. We need to close the loop faster — and we need audit evidence that we’re doing it. I want you to evaluate whether an agentic AI assistant can help."
Your assignment: Design and progressively build an autonomous AI incident response assistant, or AIOps Team, using LangChain’s Deep Agents framework. It should triage Kira tickets, investigate Ansible Controller job failures against your VM and OpenShift infrastructure, and either resolve them or surface them to the right person — with a full, compliance-ready audit trail. The AIOps Team should be able to handle multiple times the current volume of tickets and job failures, and should be able to do so with a fraction of the current human effort. You should also be able to swap out the models used by the AIOps Team to optimize for cost, capability, and compliance tradeoffs.
Meridian Financial’s challenges
The situation: Meridian Financial handles ~40 failure tickets per week. Each requires manual triage, investigation, and either remediation or escalation — averaging 45-90 minutes of SRE time per ticket depending on complexity. Multiply that across the team, factor in overnight failures and on-call rotations, and you have a systemic operations problem.
Regulatory context: As a financial services firm, Meridian operates under strict change management and incident response requirements. Every unplanned outage or configuration drift must be documented — root cause, remediation steps, responsible party — within defined SLA windows. Missing those windows triggers regulatory penalties.
Current challenges:
-
Alert fatigue: ~40 failure tickets per week, many repeating known patterns → on-call team overwhelmed, slow to respond
-
Knowledge fragmentation: Runbooks scattered across Confluence, tribal knowledge siloed in individuals → inconsistent resolution quality
-
Audit overhead: Manual incident reports for compliance → 2–3 hours per major incident, often written after the fact
-
Escalation gap: Binary choice between "fix it yourself" and "wake someone up" → no graduated, proportional response
The opportunity: Agentic AI can triage, investigate, and act — with a full audit trail — while keeping humans appropriately in the loop for high-risk changes.
What success looks like
By the end of this workshop, you’ll have hands-on experience with agentic AI patterns applicable to real-world SRE operations:
-
Triage and classify Ansible Controller failures → automated ticket categorization in Kira
-
Invoke dedicated
sre_*subagents for targeted investigation → faster, more accurate root cause identification -
Apply human-in/on/out-of-loop patterns → right escalation at the right moment, no more, no less
-
Select and configure models from Red Hat OpenShift AI MaaS (Model as a Service) → optimal cost, capability, and compliance tradeoffs
-
Generate audit-ready incident reports → compliance-friendly output for regulators, automatically
Technical outcome: A working agentic AIOps team deployed in your OpenShift namespace, connected to AAP, Kira, and RocketChat.
If the agentic assistant proves effective, Meridian projects:
-
MTTR reduction: From 45 min average → target 12 min for known failure patterns
-
Audit efficiency: Auto-generated incident reports → compliance team review instead of authoring from scratch
-
Scalability: Handle 10× ticket volume without proportional headcount growth
-
Knowledge capture: Agent patterns distill runbook knowledge → self-improving operational knowledge base
-
Open source models: Lower costs and increased data sovereignty by running models on your own infrastructure
Success metric: Measurably faster, more consistent incident response that satisfies both the engineering team and the compliance auditors.
Common questions
"Is this replacing my team?" → No. The agent handles mechanical triage and routine investigation, freeing your team for complex judgment calls. Module 5 (Compliance & the Human Loop) addresses this directly — including when to keep humans firmly in the loop.
"What if the AI gets it wrong?" → You configure human-in-the-loop gates for high-risk actions. The agent proposes; your team approves. Module 5 covers guardrails, audit trails, and failure modes.
"Which model should I use?" → MaaS gives you access to: qwen3. Each module introduces MaaS model selection at the relevant touchpoint. No MaaS UI access is required — all interaction is via API.
"Do I need to be an AI expert?" → A strong ops background is all you need. LangChain’s Deep Agents framework handles the AI orchestration complexity; you focus on the operational logic and business rules.
What you’ll learn
In this workshop, you will:
-
Understand the architecture and potential of second-generation agentic AI frameworks
-
Work with autonomous Deep Agents and dedicated
sre_subagents -
Evaluate Open Source and Frontier model tradeoffs in a regulated environment
-
Apply human-in/on/out-of-the-loop patterns to real incident response workflows
-
Architect context-aware agents using skills, subagents, and context isolation
-
Reduce MTTR and improve SLA adherence through AI-augmented operations
Who this is for
This workshop is designed for platform engineers, SREs, and DevOps practitioners who manage automation infrastructure and want to understand how agentic AI can augment — not replace — their operational expertise.
Experience level: Intermediate — strong on Ops, exploring Agentic AI
Prerequisites
Before starting this workshop, you should have:
-
Familiarity with Ansible Automation Platform (running jobs, reading output)
-
Basic understanding of OpenShift or Kubernetes concepts (namespace, pod, service)
-
Comfort working in a Linux terminal
-
No prior AI or LLM experience required
Workshop environment
Your lab environment is pre-provisioned with everything you need. Access each service via the tab bar at the top of the right panel:

| Tab | Console | What it does |
|---|---|---|
|
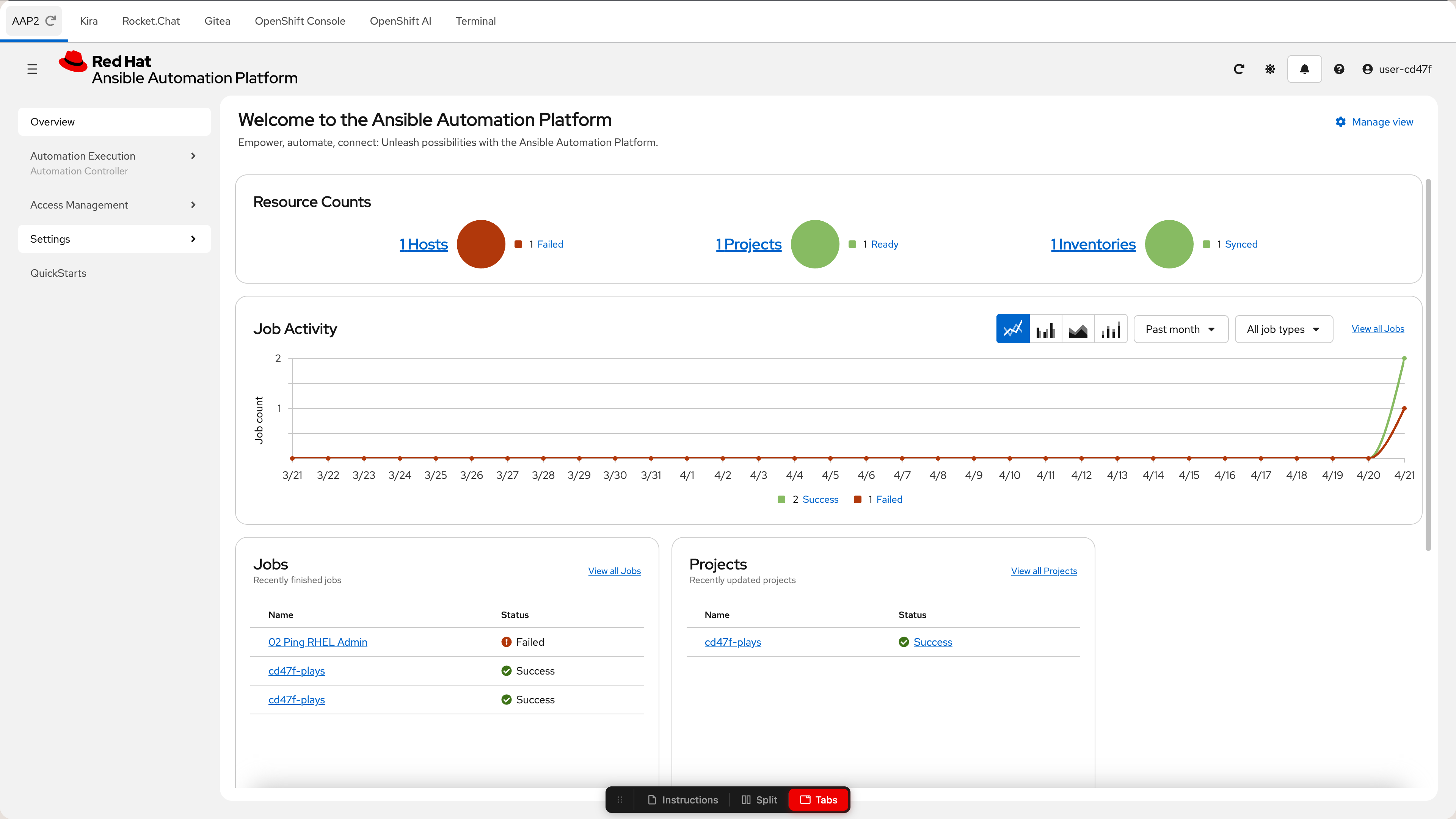
AAP2 |
Ansible Automation Platform — where automation jobs run and fail |
|
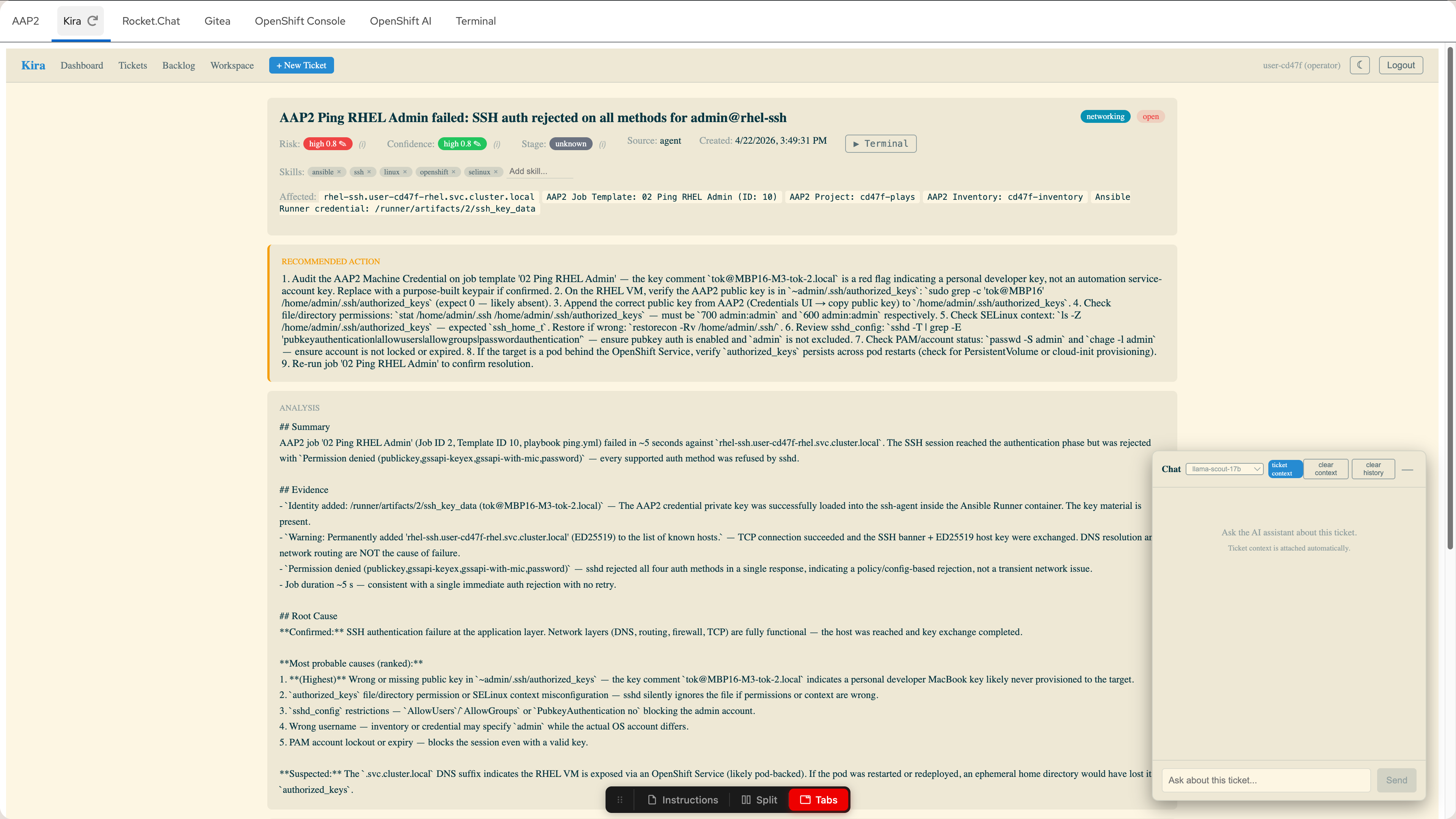
Kira |
Trouble ticketing — where your AI assistant creates structured incident tickets |
|
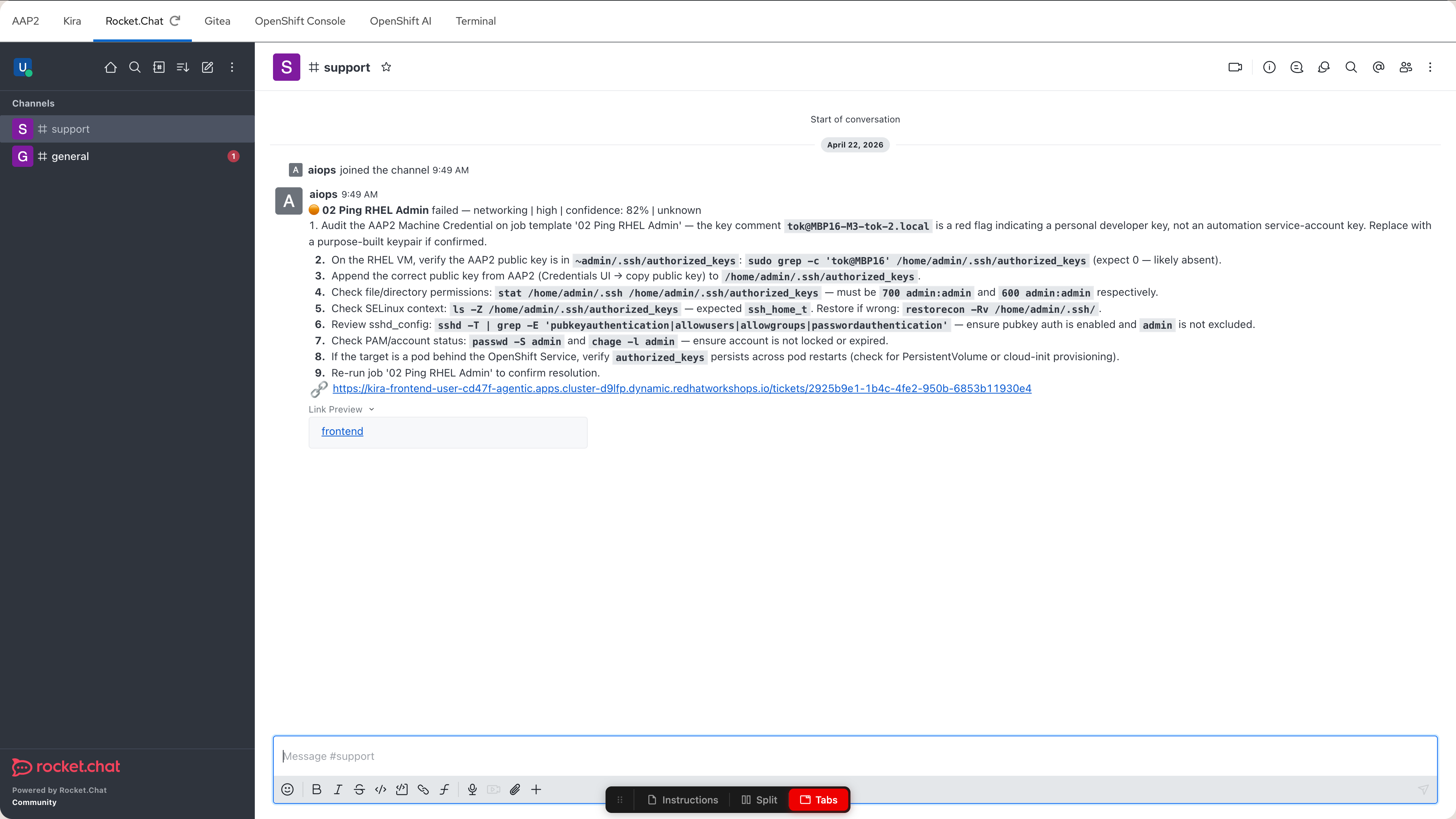
Rocket.Chat |
ChatOps — where your AI assistant posts failure notifications |
|
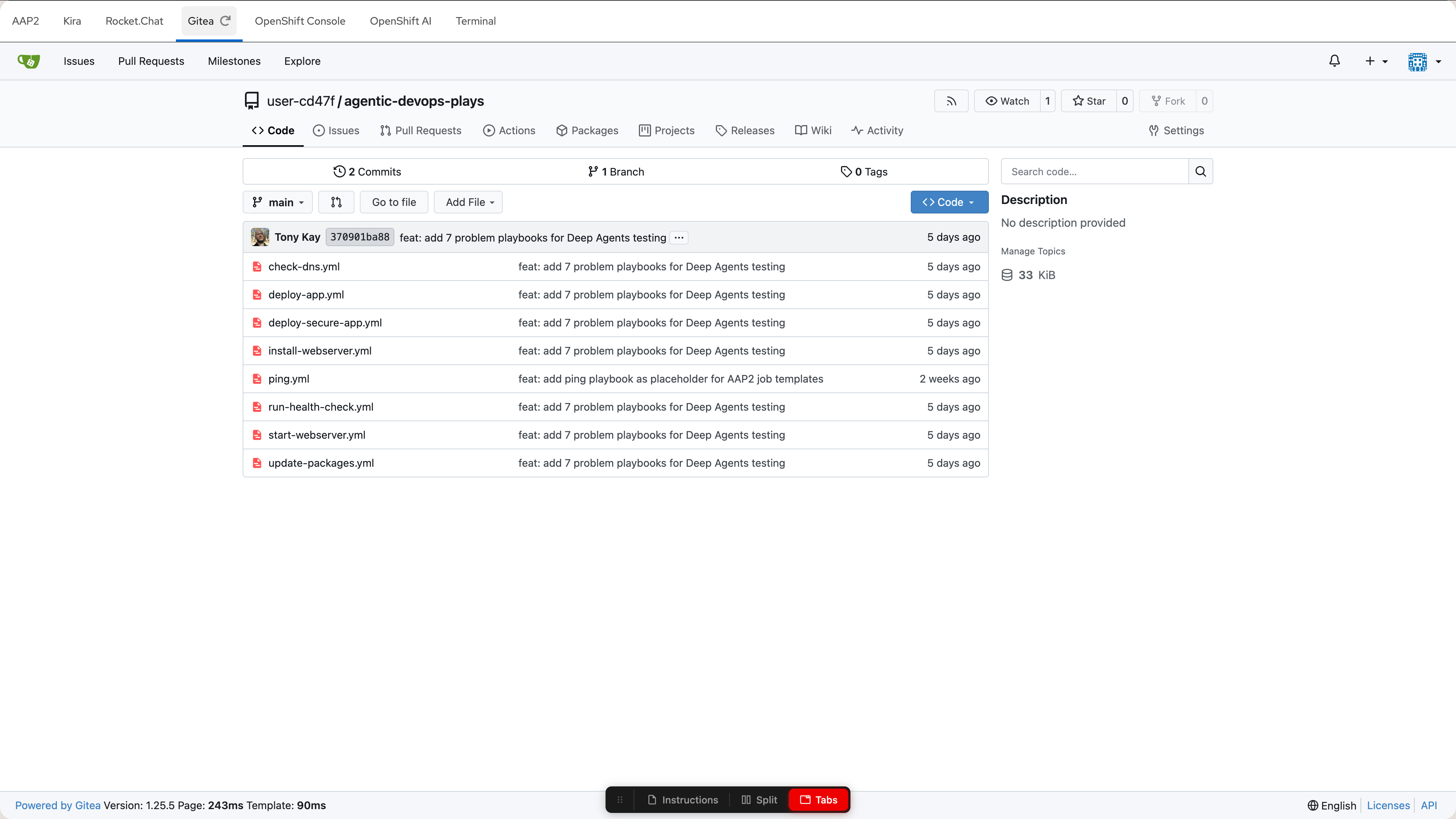
Gitea |
Source control — hosts the Ansible playbooks behind each job template |
|
OpenShift Console |
Cluster management — inspect pods, logs, and configuration |
|
OpenShift AI |
Red Hat OpenShift AI dashboard — available for later modules |
|
Terminal |
Two terminal windows for CLI work ( |
To log in to the OpenShift cluster, click the Terminal tab and paste:
oc login --insecure-skip-tls-verify \
-u user-12345 \
-p deeper-agents \
https://openshift.example.com:6443 \
--namespace user-12345-agentic| All environment details and credentials are shown in the lab interface. You do not need to install anything locally. |
Estimated time
This workshop takes approximately 90 minutes, with ~70 minutes of hands-on exercises.
Work at your own pace — your environment stays active throughout the session.