Architecture
Discover how the voice agent application is built — the voice sandwich pattern, model stack, data flow, and performance considerations.
The Voice Sandwich
The "voice sandwich" pattern wraps an LLM agent between speech-to-text (STT) and text-to-speech (TTS) layers:

Current Stack
-
Python WebSocket server
-
Next.js client
-
LangChain agents SDK (LangGraph)
-
WebSockets for client-server communication
-
RHOAI 3.x Platform on AWS
Model Selection
| Model Name | License | Description | Notes |
|---|---|---|---|
Whisper |
Speech to Text |
Quantized version of openai/whisper-large-v3-turbo whisper-large-v3-turbo-quantized.w4a16 |
|
Higgs-Audio |
Text to Speech |
Audio foundation model github higgs-audio-v2-generation-3B-base |
|
Llama4 Scout |
Agent Model |
Voice Flow
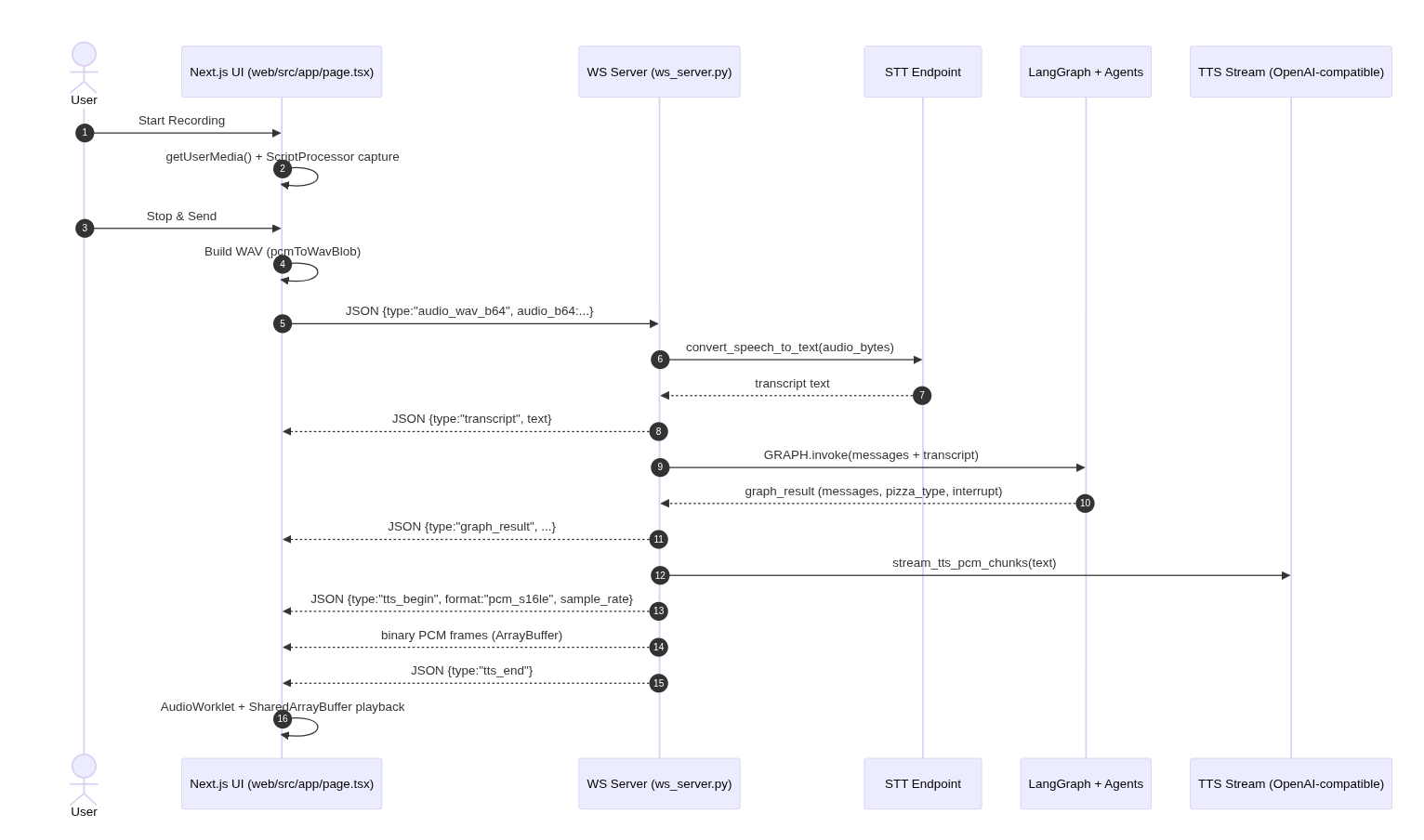
The user records audio in the browser, the UI sends the WAV to the Python WebSocket server, the server runs STT + the agent graph, then streams TTS audio back to the browser for playback.
Infrastructure Performance
Prevent buffering and choppy sound when generating speech.
GPU Performance
Measure Text to Speech generation speed to ensure smooth, real-time playback:
(gen x) = (audio seconds produced) / (wall clock seconds elapsed)-
If
gen x < 1.0for significant periods, the TTS stream is arriving slower than realtime — you will get underruns/chops unless you add more buffering (delay) or pause/rebuffer. -
If
gen x >= 1.0consistently, smooth playback is achievable. Above 2.0x provides excellent real-time performance.
In this workshop, you’ll deploy TTS on a MIG 2g.35gb slice and measure generation speed during the models module. Expect gen-x values around 2–3x real-time.

Client Architecture
Javascript client architecture using SharedArrayBuffer ring — shared-memory ring buffer (SharedArrayBuffer + Atomics) between main thread and worklet to eliminate per-chunk messaging entirely.
Next Steps
Now that you understand the voice sandwich architecture and performance considerations, let’s deploy the speech models and measure their generation speed in action.
Continue to Speech Models to deploy Whisper (STT) and Higgs-Audio (TTS).