Voice Agents: Build an AI Voice Agent Workshop
Welcome to the Voice Agents workshop! In this hands-on session, you’ll build a production voice AI pipeline by deploying speech models, orchestrating multi-agent workflows, and measuring real-time performance.
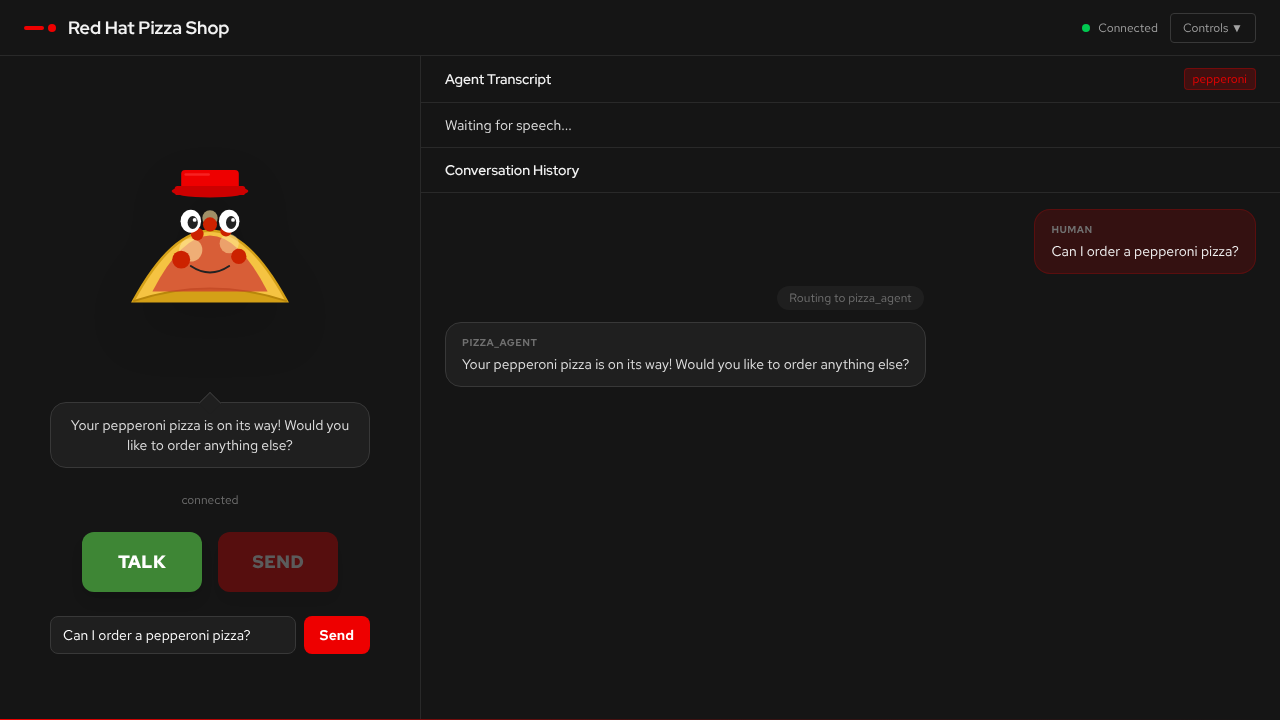
You’ll work in notebooks and terminal deploying models to OpenShift AI and benchmarking TTS generation speed (gen-x metrics). The Pizza Shop Demo showcases the complete voice agent in action — during the exercises you’ll deploy the models powering it, measure their performance, and have a spoken conversation about pizza.
What you’ll learn
In this workshop, you will:
-
Deploy speech models — set up Whisper (STT) and Higgs-Audio (TTS) on GPU MIG slices using KServe and vLLM
-
Build a voice agent — deploy a multi-agent LangGraph application that takes pizza orders via spoken conversation
-
Measure TTS performance — understand gen-x (generation speed vs real-time) and why GPU selection matters for voice quality
Understanding and navigating the workshop UI
The workshop interface is designed to let you read instructions while working in your environment.
Left panel: Workshop instructions and content
Right panel: Embedded environment for hands-on exercises
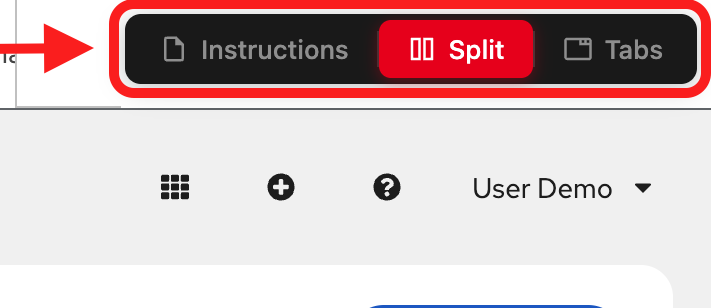
View modes (top navigation):
-
Instructions: Full-page instructions (hide environment tabs)
-
Split: Side-by-side view (current default) - see both instructions and environment
-
Tabs: Full-page environment (hide instructions)
Adjusting the layout: In Split mode, drag the middle divider left or right to resize the panels.
The app
The pizza shop voice agent follows the voice sandwich pattern — STT and TTS layers wrap an LLM agent graph. You speak into the microphone, a supervisor agent routes your request to specialist agents (pizza, order, delivery), and the response is spoken back to you in real-time.

The voice agent operates as a multi-agent graph using LangGraph:
-
Browser captures microphone audio and sends WAV over WebSocket
-
Whisper transcribes the audio to text
-
A supervisor agent analyses intent and routes to the right specialist
-
Specialist agents (pizza, order, delivery) handle their domain using tools
-
Higgs-Audio converts the response text to speech
-
PCM audio streams back to the browser in real-time (~20ms chunks)
The AI agent
The system uses a supervisor pattern — one agent coordinates several specialists:
| Agent | Role |
|---|---|
Supervisor |
Analyses user intent and routes to the right specialist. Handles general conversation directly. |
Pizza Agent |
Knows the menu, helps you pick toppings and pizza types. Has access to menu lookup tools. |
Order Agent |
Calculates totals, manages quantities, and summarises your order. |
Delivery Agent |
Collects delivery address and timing preferences. |

The agent uses LangGraph with the ReAct (Reason + Act) pattern — at each step it observes the conversation state, decides which specialist to route to, and adapts based on your requests.
Understanding gen-x
For real-time voice agents, gen-x (generation speed) is the critical metric. It measures how fast the TTS model produces audio compared to real-time playback:
gen x = audio seconds produced / wall clock seconds elapsed
| gen x | What It Means |
|---|---|
< 1.0x |
Choppy playback, gaps in speech. The model can’t keep up with real-time. |
1.0—2.0x |
Smooth but with occasional micro-pauses during complex responses. |
> 2.0x |
Smooth, natural-sounding speech with no perceptible delay. |
GPU selection drives gen-x. An L4 GPU delivers ~0.78x (too slow for smooth voice), while an H200 MIG slice achieves 2—3x. You’ll measure this yourself during the speech models module.

Workshop modules
In this workshop you’ll work through these modules:
-
Architecture — The voice sandwich pattern, model stack, WebSocket data flow, and gen-x performance
-
Speech Models — Deploy Whisper (STT) and Higgs-Audio (TTS) on GPU MIG slices, test the APIs, and measure generation speed
-
Pizza Shop Demo — Deploy the multi-agent voice app with Helm, connect everything together, and have a spoken conversation about pizza
Who this is for
This workshop is designed for AI/ML engineers, platform engineers, and developers who want hands-on experience with:
-
Voice-enabled AI applications (STT + LLM + TTS)
-
Multi-agent orchestration with LangGraph
-
Model serving on OpenShift AI with vLLM and KServe
Experience level: Beginner to Intermediate
|
All images have lightbox attached to them so they can overlay on top of the web page so you can see them. Just click on them! (and click to minimize again) |