Guide
What You’re Seeing
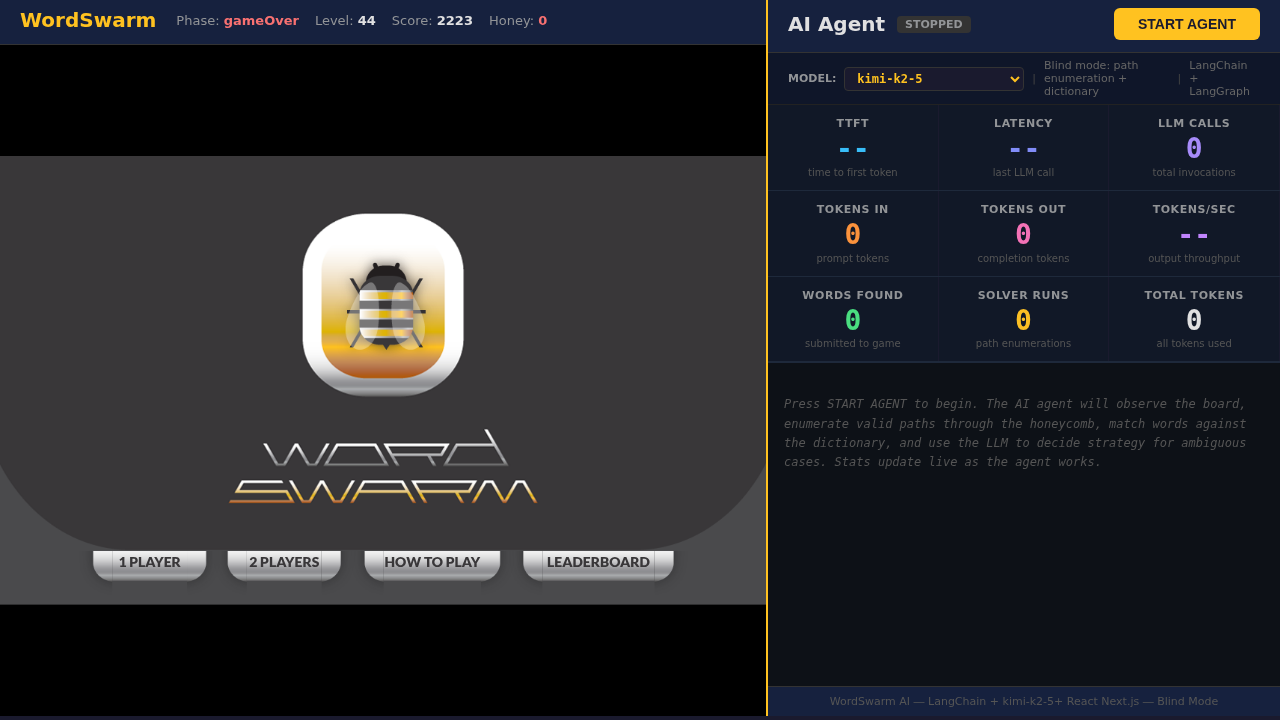
This demo is a split-screen dashboard where an AI agent plays a honeycomb word game in real time.
-
Left panel — The Game. A live WordSwarm puzzle. Letters sit on 17 hexagonal cells and words are formed by dragging across adjacent cells.
-
Right panel — The Agent. Controls, live stats, and a scrolling log of the AI agent’s actions and reasoning as it plays autonomously.
When you press START AGENT, a Python process launches on the server. It observes the board, searches for words, and submits them — all without ever seeing the answer key.
How It Works
-
Agent observes: reads the board state (letters, hints, visible cells) via the Blind API
-
Solver enumerates: DFS through the 17-node adjacency graph finds all valid letter paths (3-6 letters)
-
Dictionary match: each path is checked against a 1,677-word dictionary in ~4ms
-
Hint matching: found words are matched against the hint list (first letter + length + revealed letters)
-
LLM resolves ambiguity: when multiple dictionary words match the same hint, the LLM reasons about which one fits
-
Agent submits: the chosen word is queued as a simulated drag sequence and the game client replays it
Game Mechanics
Objective
Find hidden words on the honeycomb before time runs out. Each correct word raises the honey level. If the honey drops to zero, the round ends.
How Words Work
-
Words are 3-6 letters long, laid across adjacent hexagonal cells
-
Each cell can only be used once per word
-
The word list shows hints: the first letter is always visible; remaining letters are revealed as words are solved
-
A correct word lights up green; an incorrect guess shows a red X and drains honey
What to Observe
As the agent plays, pay attention to the stats panel and log output. Here is what each metric tells you:
Speed Metrics
| Metric | What It Means |
|---|---|
TTFT |
Time to First Token — how long before the model starts responding. Bounded by network latency and model load. |
Latency |
Total wall-clock time for each LLM call, including all token generation. |
Tokens/sec |
Output throughput. Higher means the model generates text faster. |
Cost Metrics
| Metric | What It Means |
|---|---|
Tokens In |
Prompt tokens sent to the model (context, instructions, game state). |
Tokens Out |
Completion tokens generated by the model (reasoning, tool calls). |
Total Tokens |
Combined usage. In production, this drives cost. |
Effectiveness Metrics
| Metric | What It Means |
|---|---|
Words Found |
How many words the agent successfully submitted. |
Solver Runs |
How many times the path-enumeration solver scanned the board. |
LLM Calls |
Total invocations. More calls = more reasoning steps. Watch the ratio of calls to words found. |
Reasoning Transparency
Every agent action is logged with full reasoning:
[Agent] Calling tool: find_words
[Agent] Found 12 candidates, 8 certain, 4 ambiguous
[Agent] Submitting 8 safe words...
[Agent] Calling tool: submit_word_by_name("HASTE")
→ LLM resolved ambiguity: HASTE vs PASTE — chose HASTE based on
hint H____ (first letter matches)
This transparency is crucial for understanding and trusting agentic AI systems.
Key Concepts
Agentic AI
Traditional AI answers questions. Agentic AI takes actions in a loop: observe, reason, act, repeat.
| Traditional AI | Agentic AI |
|---|---|
Responds to individual prompts |
Pursues goals autonomously |
Generates text or answers |
Makes decisions and takes actions |
Stateless interactions |
Maintains context across steps |
Requires human direction each step |
Plans and executes multi-step tasks |
Static behavior |
Adapts to changing circumstances |
This agent uses the ReAct (Reason + Act) pattern powered by LangGraph. At each step it decides which tool to call — observe the board, run the solver, or submit a word — based on the current game state and its own prior reasoning.
Unlike a script, the agent adapts. If the solver returns ambiguous matches, the LLM reasons about which word fits best. If the board changes mid-turn, it re-observes and re-plans.
Reasoning Models
Some models (like kimi-k2-5) use internal "chain of thought" before producing a visible answer. This shows up as reasoning tokens — tokens the model generates for itself, not shown to the user.
Reasoning models often produce better decisions (fewer wrong guesses) but consume more tokens and take longer per call. Watch the Tokens Out counter — a reasoning model may show high output even when the visible response is short.
The trade-off: accuracy vs. speed. A reasoning model may solve the puzzle in fewer attempts but take longer per move. A faster model may guess more but act quickly.
Use the /think and /no-think prompting patterns to control reasoning behavior at runtime. Module 1 covers this in detail.
|
Performance & Efficiency
The demo measures what matters in production AI systems:
-
Latency — Can the agent act fast enough to keep the honey level from dropping? This mirrors real-time requirements in production (chat, automation, monitoring).
-
Token efficiency — How many tokens does it take to find each word? Fewer tokens per result = lower cost at scale.
-
Tool use — The agent has specialized tools (solver, observer). Good agents call the right tool at the right time instead of reasoning from scratch every step.
-
Blind mode — The agent never sees the answer key. It must discover words through graph traversal and dictionary lookup, just like a human player. This demonstrates real-world constraints where AI operates with incomplete information.
Real-World Applications
The concepts demonstrated in this demo apply to production AI systems:
-
DevOps & SRE — Autonomous incident response, self-healing infrastructure, intelligent resource scaling
-
Business process automation — Intelligent workflow routing, dynamic resource allocation, adaptive scheduling
-
Data engineering — Autonomous pipeline management, intelligent quality monitoring, self-tuning operations
-
Customer service — Multi-turn problem solving, context-aware support agents, proactive issue detection
Powered by Red Hat OpenShift AI
The models are served through Red Hat OpenShift AI Model As A Service (MaaS):
-
Scalable model serving for multiple concurrent requests via vLLM
-
Low latency inference enabling real-time agent decision-making
-
Enterprise security with API authentication and network policies
-
Optimized serving with quantized models for cost efficiency