Workshop overview
Background
We took a 14-year-old open source word game — originally built for Intel in 2012 — and bolted an AI agent onto it. The idea was simple: could an agent play a real-time honeycomb puzzle game, and if so, which of the models in our MaaS platform would come out on top?
We migrated the game from Java/Tomcat/jQuery to React/Next.js, wrote a blind solver in Python, wired it up to LangGraph, and pointed four different LLMs at the leaderboard to find out.
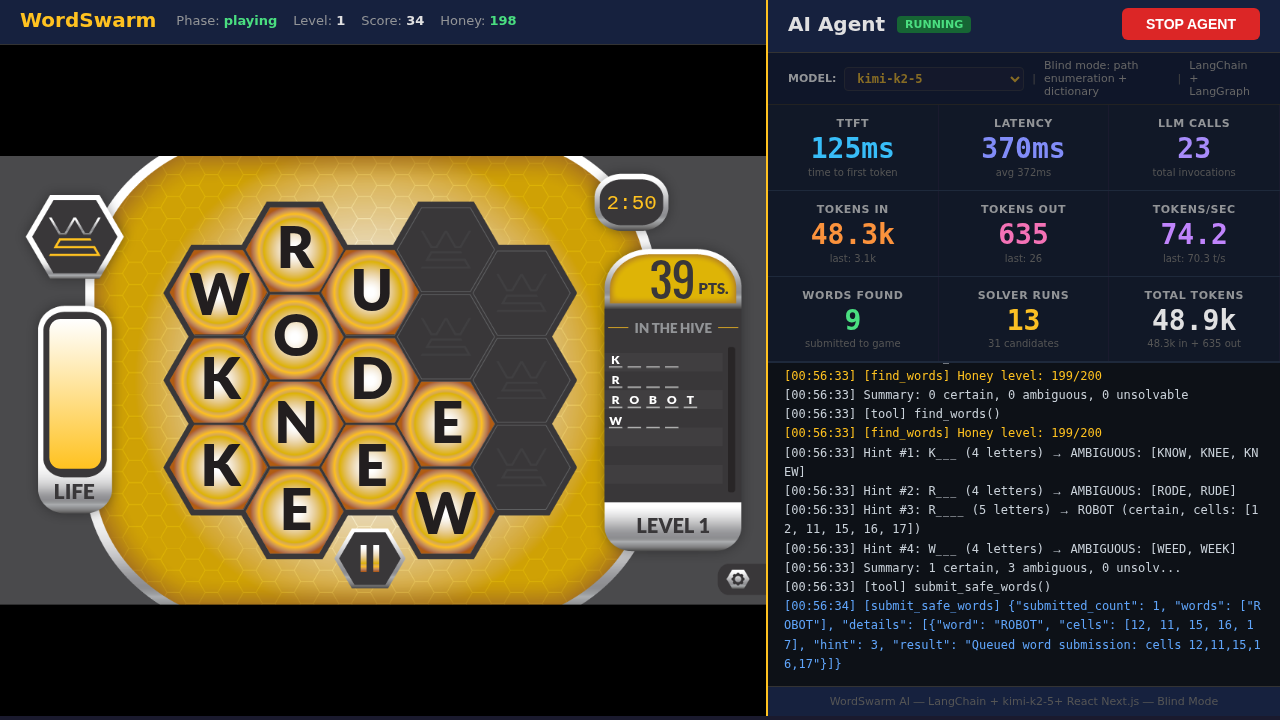
How the agent works
The agent operates in blind mode — it can’t see the word list. It:
-
Enumerates adjacency paths through a 17-cell hex grid (DFS, ~4ms)
-
Matches paths against a dictionary (hash set, O(1) lookup)
-
Uses the LLM to resolve ambiguous cases (multiple words fit the same hint)
-
Submits words faster than the honey drains
The leaderboard results
Here’s what fell out after 13 runs across 4 models:
| Model | GPUs | Score | Level | Words | Accuracy | Tokens | Avg Latency | t/s |
|---|---|---|---|---|---|---|---|---|
kimi-k2-5 |
8x H200 (TP=8) |
1,038 |
21 |
284 |
65% |
4.0M |
977ms |
58.6 |
nemotron-cascade-2-30b |
1x MIG-3g.71GB |
264 |
6 |
76 |
59% |
1.9M |
2.0s |
128.6 |
llama-4-scout-17b (W4A16) |
2x MIG-3g.71GB |
153 |
4 |
34 |
76% |
366k |
516ms |
34.9 |
llama-3.2-3b-instruct |
1x MIG-1g.18GB |
36 |
1 |
10 |
80% |
34k |
567ms |
54.9 |
Key observations
Larger reasoning models play better — kimi-k2-5 dominates at 1,038 points, nearly 4x the next best score. It follows the game loop, handles ambiguity, and stays calm under pressure. Smaller models wander off, narrate their thoughts, and burn the clock.
The input token burn rate is extreme — every model burns 97-99%+ of tokens on input. kimi-k2-5’s best run consumed 4M tokens: 3.98M input, 31k output. This is inherent to the ReAct agent loop pattern — each invocation replays the full conversation history.
Workshop modules
In this workshop you’ll explore two key aspects:
-
Module 1: Reasoning Prompting — Use
/thinkand/no-thinkto control how models reason through problems -
Module 2: GuideLLM Benchmarking — Measure model throughput, latency, and concurrency using synthetic benchmarks
Click Module 1 in the navigation to begin.