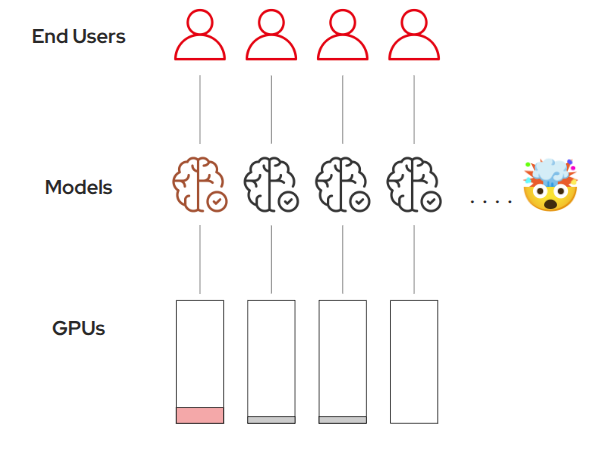
Introduction: The Hidden Cost of Infrastructure-as-a-Service
When infrastructure is self-service with no clear guardrails in place, problems can quickly emerge:
-
Teams struggle to correctly request and size GPU resources
-
Multiple teams may deploy identical models, duplicating effort
-
Expensive GPUs remain idle or become overloaded
-
Infrastructure costs escalate without clear accountability
-
Developers need model access, not GPU management complexity
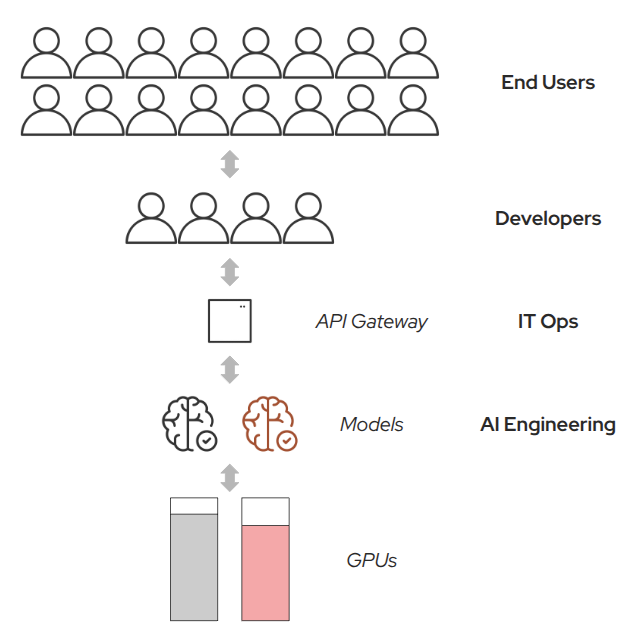
Models-as-a-Service: A Better Abstraction for AI at Scale
To address these challenges as a platform engineer, you will design a centralized, reusable, and secure model-serving layer:
Centralized Model Management
-
Platform teams deploy and maintain models with proper lifecycle management
-
Versioning, rollbacks, and testing become standardized processes
Secure API Gateway
-
All model access goes through authenticated, rate-limited endpoints
-
Full observability and monitoring across all model interactions
Developer-Friendly Access
-
Developers consume models without managing underlying hardware
-
Teams focus on building applications, agents, and features powered by AI
Efficient Resource Utilization
-
GPU resources are pooled and shared across the organization
-
Eliminates waste while ensuring fair access and cost control