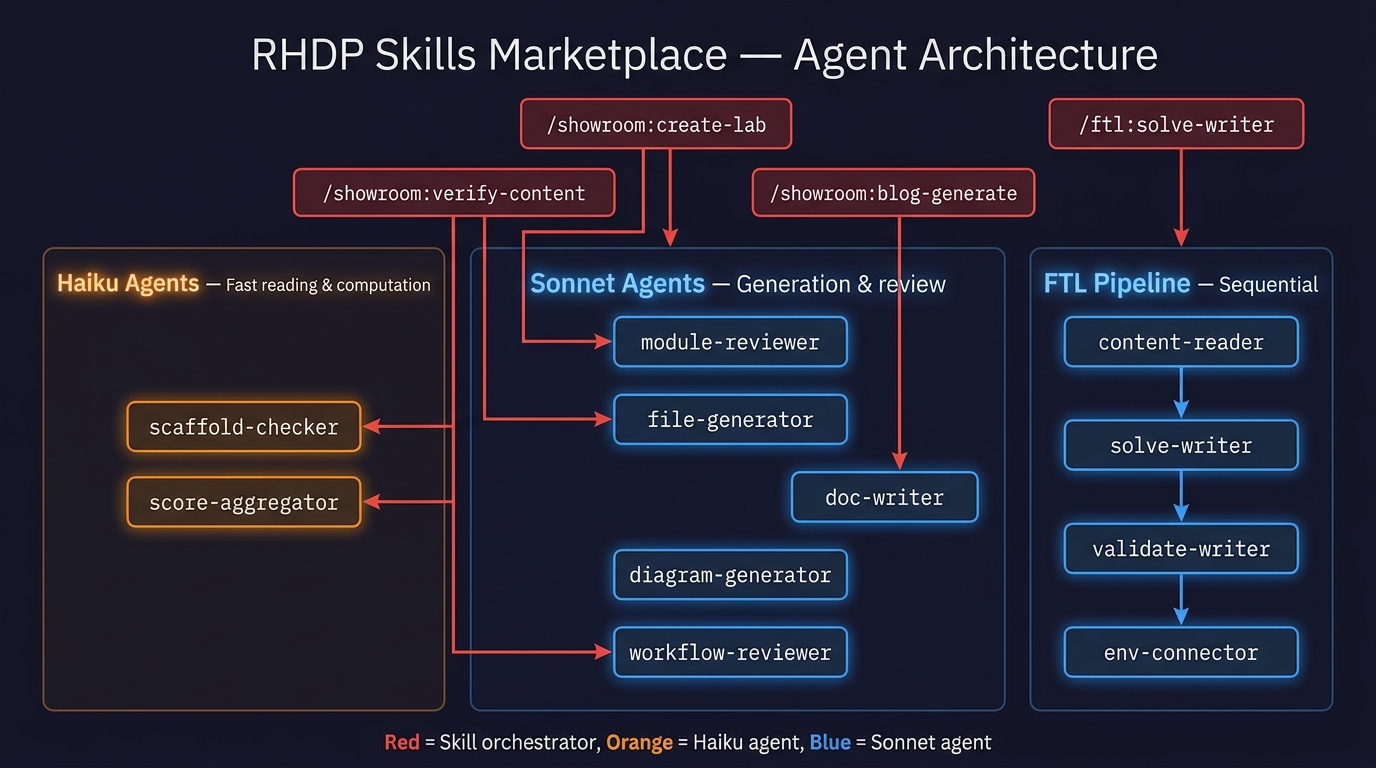
Agent Architecture
The RHDP Skills Marketplace follows the skill-as-orchestrator, agent-as-worker pattern — the same design used by the FTL plugin.
Core Principle
Skills handle user interaction and coordination. Agents do the actual work in parallel, each with a fresh context window.
Why agents instead of inline checks?
| Old approach | Agent approach |
|---|---|
| All checks in one context window | Each agent gets a fresh context — no saturation |
| Sequential — each check waits for the previous | Parallel — N modules reviewed simultaneously |
| 8 minutes for a 6-module lab | ~90 seconds (6× faster) |
| Model sees everything — can’t score dimensions | Each agent returns structured JSON — eval-ready |
All Agents
Showroom Plugin
| Agent | Model | Purpose | Called by |
|---|---|---|---|
showroom:scaffold-checker |
Haiku | Checks site.yml, ui-config.yml, antora.yml, gh-pages.yml | verify-content |
showroom:module-reviewer |
Sonnet | Reviews one .adoc module — B/C/D/E/F checks + dimension scores | verify-content, create-lab, create-demo |
showroom:file-generator |
Sonnet | Generates one AsciiDoc file (or Markdown blog) from spec | create-lab, create-demo, blog-generate |
showroom:score-aggregator |
Haiku | Aggregates dimension scores, detects regressions vs baseline | showroom:eval (future) |
showroom:doc-writer |
Sonnet | Generates/updates GitHub Pages docs from SKILL.md | any skill after changes |
FTL Plugin (reference pattern)
| Agent | Model | Purpose |
|---|---|---|
ftl:content-reader |
Sonnet | Reads .adoc, extracts tasks and classifies steps |
ftl:solve-writer |
Sonnet | Writes solve.yml from content-reader output |
ftl:validate-writer |
Sonnet | Writes validate.yml playbooks |
ftl:env-connector |
Sonnet | Pushes to live showroom, runs test cycle |
AgnosticV Plugin
| Agent | Model | Purpose |
|---|---|---|
agnosticv:workflow-reviewer |
Sonnet | Checks builder/validator skill consistency |
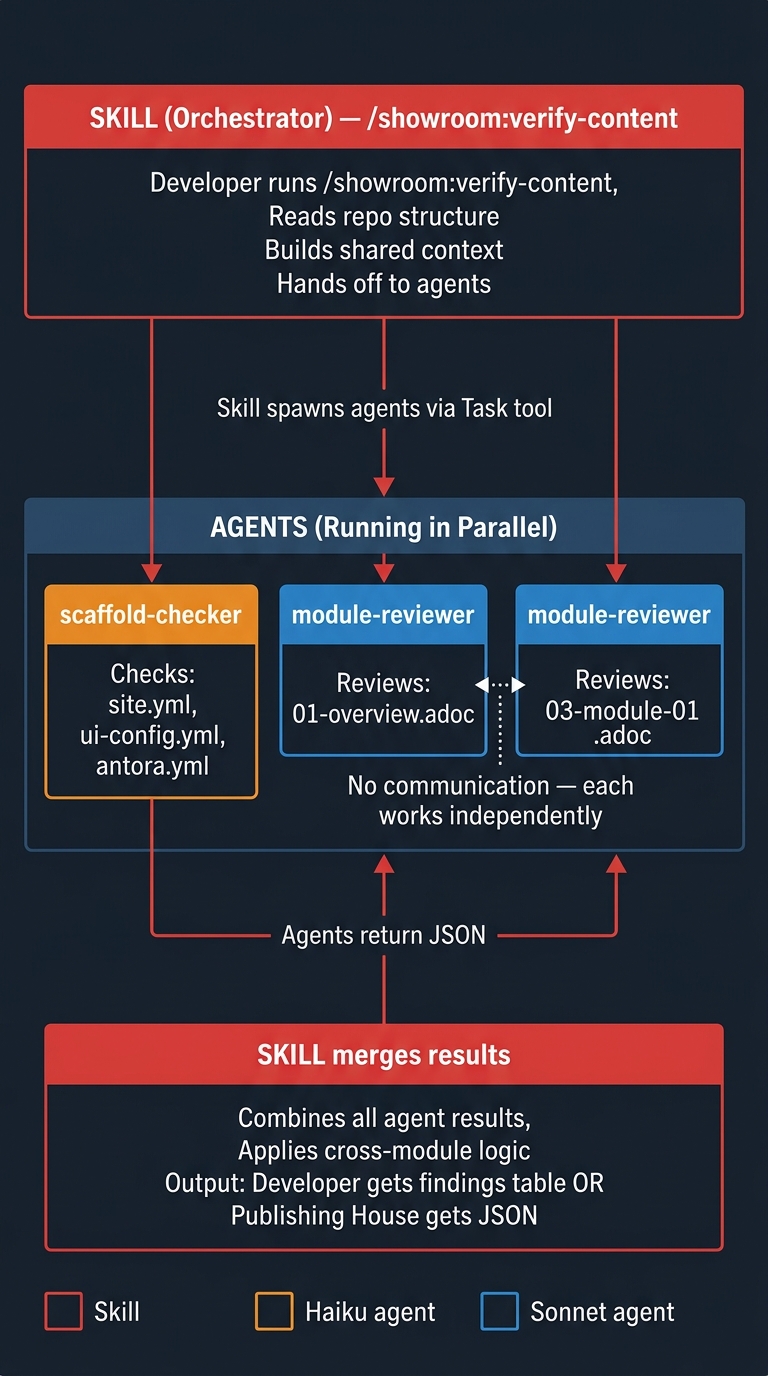
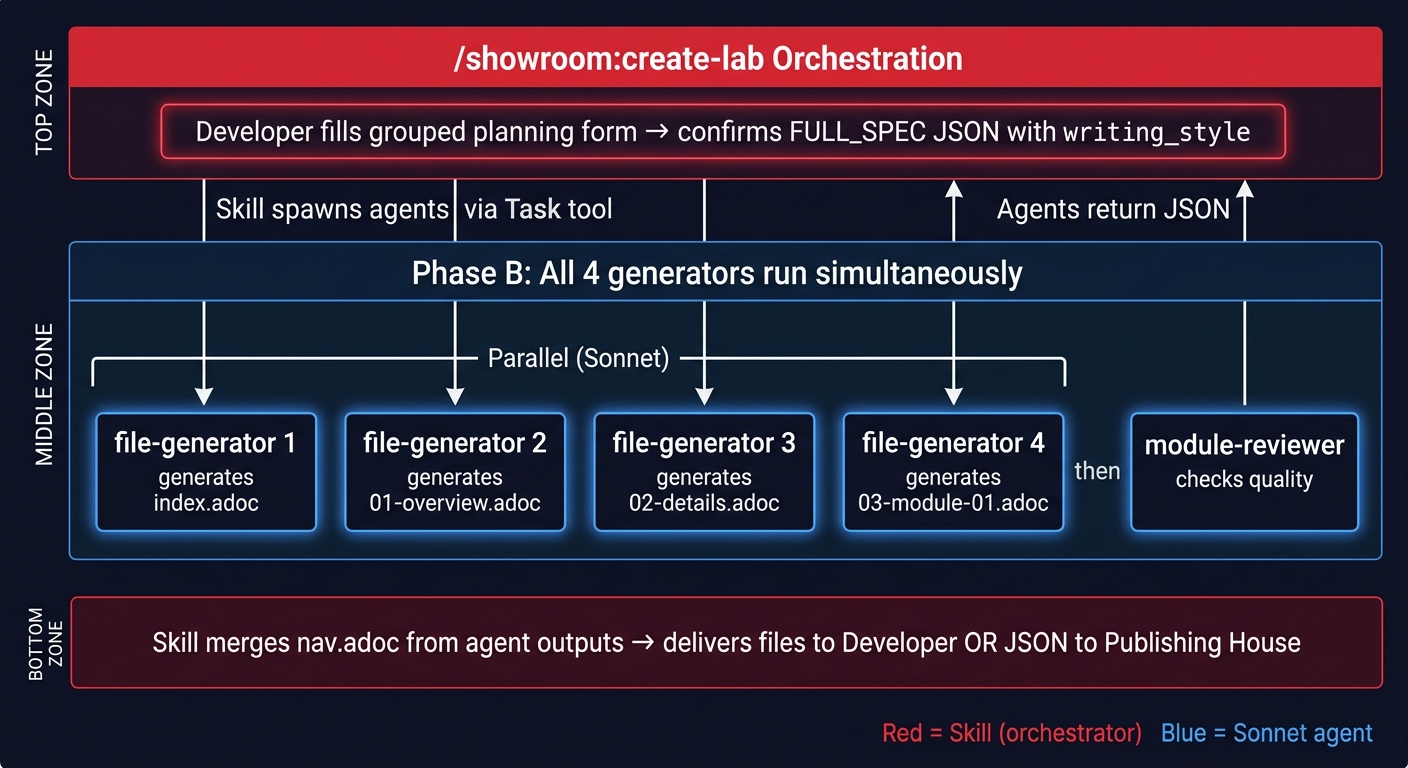
How Skills Spawn Agents
Skills use the Task tool with subagent_type:
Task tool:
subagent_type: showroom:module-reviewer
prompt: |
MODULE_FILE: /path/to/03-module-01.adoc
CONTENT_TYPE: workshop
LAB_TYPE: ocp
SHARED_CONTEXT: {"module_order": [...], "defined_attributes": {...}}
REPO_PATH: /path/to/repo
All agents return structured JSON only — no prose, no tables. The orchestrating skill handles presentation.
verify-content Orchestration
create-lab Orchestration
Model Assignments
| Tier | Model | Used for |
|---|---|---|
| Orchestrators | Sonnet 4.6 | All skills — user interaction + coordination |
| Generation/review agents | Sonnet 4.6 | module-reviewer, file-generator, doc-writer, workflow-reviewer |
| Reading/computation agents | Haiku 4.5 | scaffold-checker, score-aggregator |
| FTL agents | Sonnet 4.6 | content-reader, solve-writer, validate-writer, env-connector |
Skill Evaluation Framework
One of the most important aspects of this architecture is that agent outputs are structured JSON with dimension scores — making the skills measurable and comparable across versions.
The Challenge
Evaluating content creation skills is hard:
- Did a change improve introduction quality but degrade the main body?
- Is the skill now better at RHEL labs but worse at OpenShift labs?
- Did adding a rule improve style compliance but hurt pacing?
The agnosticv:validator is the easy case — formal rules, deterministic output, pass/fail clear. Evaluating create-lab is genuinely hard.
What the Score-Aggregator Enables
The showroom:score-aggregator (Haiku) receives module-reviewer JSON outputs and produces:
{
"dimensions": {
"structure": {"current": 0.88, "baseline": 0.85, "delta": "+0.03"},
"pedagogy": {"current": 0.72, "baseline": 0.78, "delta": "-0.06 ⚠️"},
"style": {"current": 0.94, "baseline": 0.93, "delta": "+0.01"},
"intro_quality": {"current": 0.91, "baseline": 0.84, "delta": "+0.07"}
},
"verdict": "REGRESSION — pedagogy degraded by 0.06 on OCP labs",
"lab_type": "ocp"
}
This catches the case where “intro_quality improved but pedagogy regressed on OCP labs” — per-dimension, per-lab-type regression detection that no single score could surface.
The Pioneer Opportunity
Skill evals for content generation skills don’t exist in the industry at this level. The patterns here — structured JSON agents, dimension scoring, golden datasets, lab_type tagging — could be applied beyond RHDP:
- Publishing House — eval before publishing, not just after
- Tailwind — same eval pipeline for any generated content
- Across Red Hat — any team generating structured technical content
The agnosticv:validator provides the immediate proof: formal output schema, automated scoring, no ambiguity. The generative skills (create-lab, create-demo) are harder but the architecture makes it possible for the first time.
See Writing Style Guide for how personal style profiles interact with the eval framework.