How to work with a Foundation Model
Models Don’t Understand Your Data
Large Language Models (LLMs) like GPT, Claude, Llama, and more are trained on vast datasets comprising internet text, books, and public code repositories. While this extensive training enables them to generate coherent and contextually relevant responses, it also introduces inherent limitations:
-
Knowledge Cutoff: LLMs possess information only up to their last training date. For instance, a model trained in 2024 won’t be aware of events or developments that occurred afterward.
-
Lack of Domain-Specific Expertise: General-purpose LLMs may struggle with specialized terminology or nuanced knowledge unique to specific industries, such as legal, medical, or technical fields.
-
Hallucinations: These models can produce plausible-sounding but factually incorrect or nonsensical answers, especially when faced with unfamiliar or ambiguous queries.
-
Bias and Representation Issues: The training data may contain biases, leading to outputs that inadvertently reflect or amplify these biases.
-
Inability to Process Proprietary or Internal Data: LLMs don’t have access to confidential or proprietary information unless explicitly provided, limiting their usefulness in enterprise contexts.

These limitations underscore the need for customizing LLMs to better align with specific organizational knowledge and requirements. Generic generative AI services and APIs, such as ChatGPT, are based on publicly available internet data and cannot address company‑specific queries. For an AI to be truly useful within a business context, it must be trained on industry data, the company’s proprietary information, and personal data related to customers and business partners—maximizing the value derived from the AI system.
Customizing LLMs: The Two Main Approaches
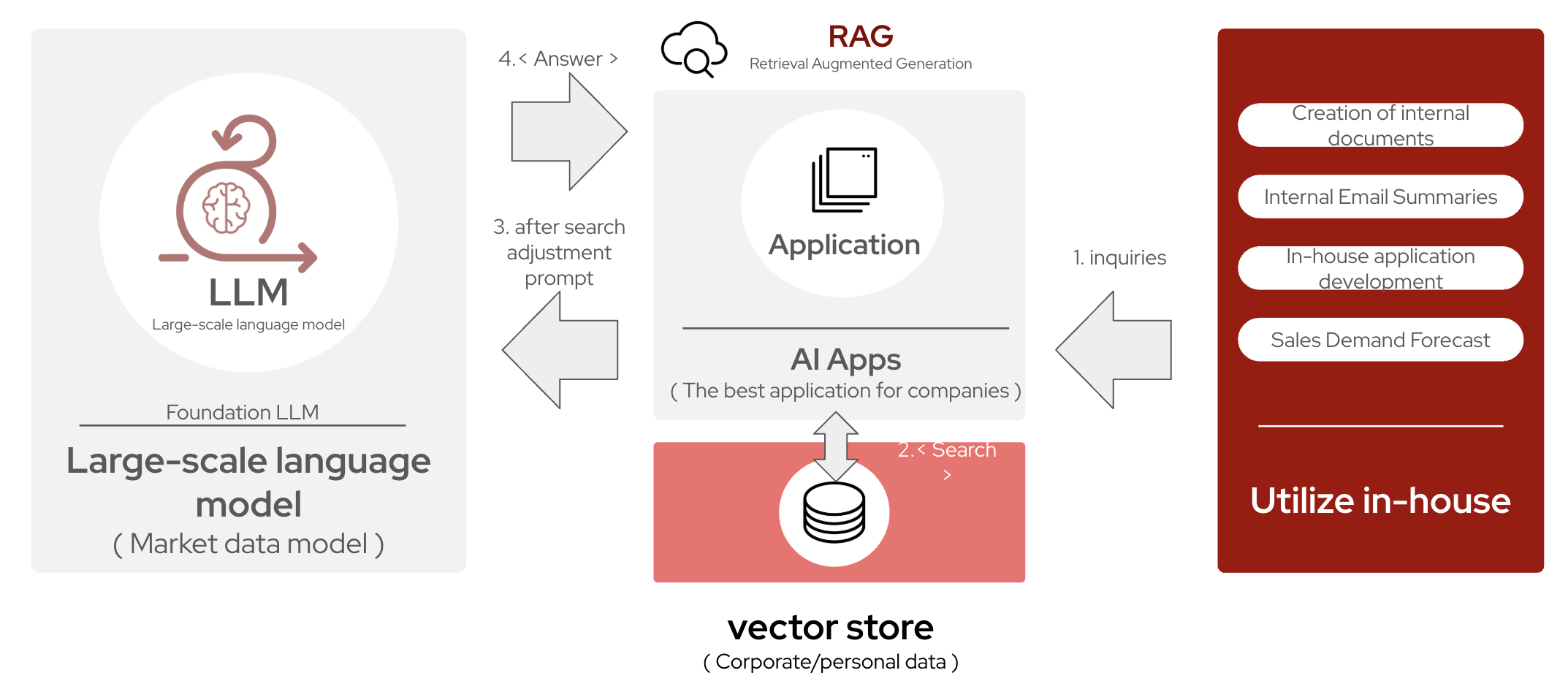
When customizing AI models, two techniques stand out: Retrieval‑Augmented Generation (RAG) and fine‑tuning. To begin, Retrieval‑Augmented Generation (RAG) is helpful when you need real‑time access to dynamic knowledge bases, especially in environments with constantly updating information. RAG allows for scalability and handles out‑of‑domain queries effectively without retraining, making it a quick solution for improving model output. However, by providing contextual information to the model for each prompt, your costs and resource usage may be higher than “baking‑in” information via fine‑tuning.
In contrast, Fine‑tuning excels when you need precise, controlled outputs for specialized tasks using curated data. It’s ideal for applications where security and compliance require embedding all data within the model. Fine‑tuning is also suitable when you have clear use cases with specific task requirements, and by integrating particular information into a model, you can improve performance, increase accuracy, and decrease model responses or latency.
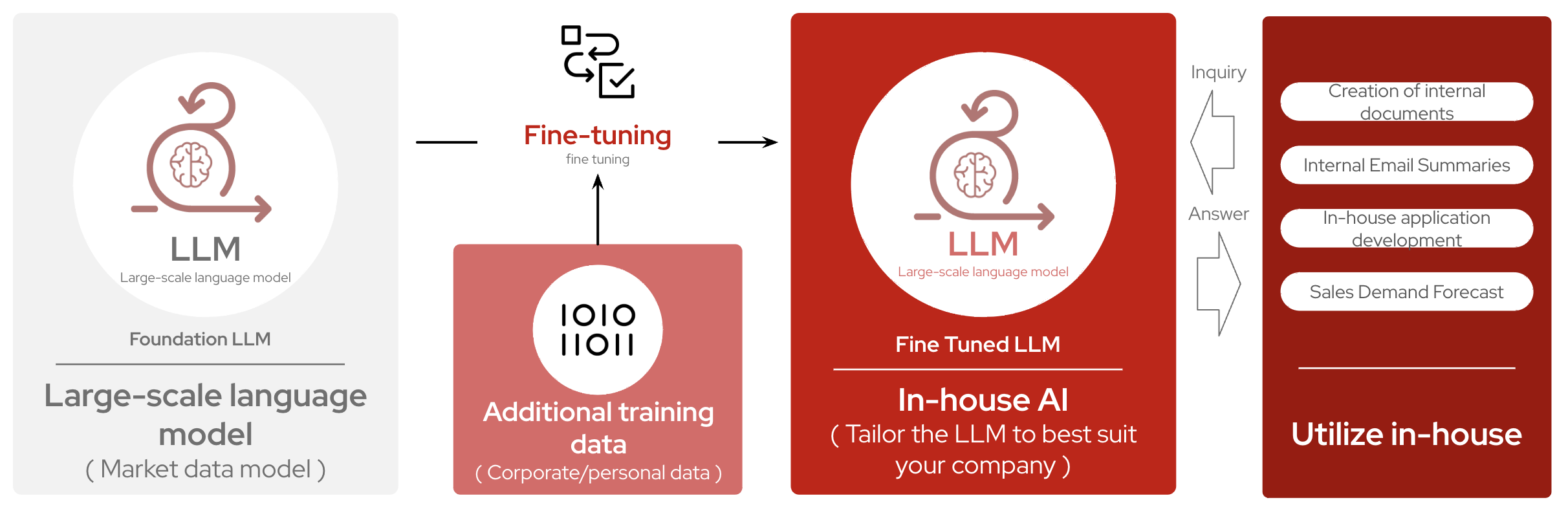
It’s important to note that it’s neither a either/or situation when customizing language models and their applications. In fact, many organizations choose to incorporate both, leading to the RAFT (RAG + Fine-Tuning) approach to achieve the highest accuracy of results for their users. Let’s start off with fine-tuning and learn how it works behind the scenes!