Integrating the LLM into your application
Application Integration: Java + Quarkus + LangChain4J
Now that you’ve tested your fine-tuned model, let’s explore how to integrate it into an actual application. In this workshop, we’ve provided a mock airline interface called Parasol Airlines, which simulates customer interactions. This web app is containerized and connected to your local model server. It allows you to:
-
Test responses in a real UI
-
Simulate customer support queries
-
Evaluate policy handling and user experiences
No frontend code or deployment setup is needed — you’ll just interact with the app to validate that your model aligns with enterprise expectations. Behind the scenes, the app uses LangChain4J to connect to your model server and handle requests. Specifically, it uses the LangChain4J library to manage the connection between the app and your model server running on port 8000, allowing for seamless communication and data exchange. The app is built with Quarkus, a Java framework that simplifies building cloud-native applications.
Start the Model Server
Before using the application, let’s ensure your model is running. You may have left the model server running from the previous step, but if not, you can start it again now.
-
In either Terminal, run the following command to start the model server if you haven’t already:
ilab model serve --model-path /home/developer/.cache/instructlab/models/404-airlines-qa.gguf
Behind the scenes, this step spins up a lightweight inference server powered by vLLM or llama.cpp, depending on your setup. Then, the Parasol Airlines Demo App can send requests and recieve requests using a standardized REST API.
|
It may take some seconds to start, but you should see the following which should look familiar to you:
INFO 2024-10-20 17:24:33,497 instructlab.model.serve:136: Using model '/home/developer/.cache/instructlab/models/404-airlines-qa.gguf' with -1 gpu-layers and 4096 max context size.
INFO 2024-10-20 17:24:33,497 instructlab.model.serve:140: Serving model '/home/developer/.cache/instructlab/models/404-airlines-qa.gguf' with llama-cpp
INFO 2024-10-20 17:24:34,492 instructlab.model.backends.llama_cpp:232: Replacing chat template:
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ '<|user|>
' + message['content'] }}
{% elif message['role'] == 'system' %}
{{ '<|system|>
' + message['content'] }}
{% elif message['role'] == 'assistant' %}
{{ '<|assistant|>
' + message['content'] + eos_token }}
{% endif %}
{% if loop.last and add_generation_prompt %}
{{ '<|assistant|>' }}
{% endif %}
{% endfor %}
INFO 2024-10-20 17:24:34,495 instructlab.model.backends.llama_cpp:189: Starting server process, press CTRL+C to shutdown server...
INFO 2024-10-20 17:24:34,495 instructlab.model.backends.llama_cpp:190: After application startup complete see http://127.0.0.1:8000/docs for API.Let’s test out the results!
Now that your model is running, switch to the Parasol Airlines tab in your environment, where you’ll see a mock airline interface. By default, you’ll be at the dashboard, where you can see various customer service inquiries that would typically be handled by a customer service agent.
-
First, click on the CASE202401 tab in the left navigation bar. This will take you to a page where you can see details about a specific case, with an example of key details and sentiment analysis that an LLM model might provide. However, we’re going to go beyond just generic model capabilities and see how our fine-tuned model can help us with specific airline inquiries.
-
In the Customer Inquiry section, you can see a sample question that a customer might ask. This is where you can test your model’s response to a specific query. Try asking domain-specific questions like:
Can this customer bring two carry-ons?
What is the refund policy for mechanical delays?
How early can they check in for an international flight?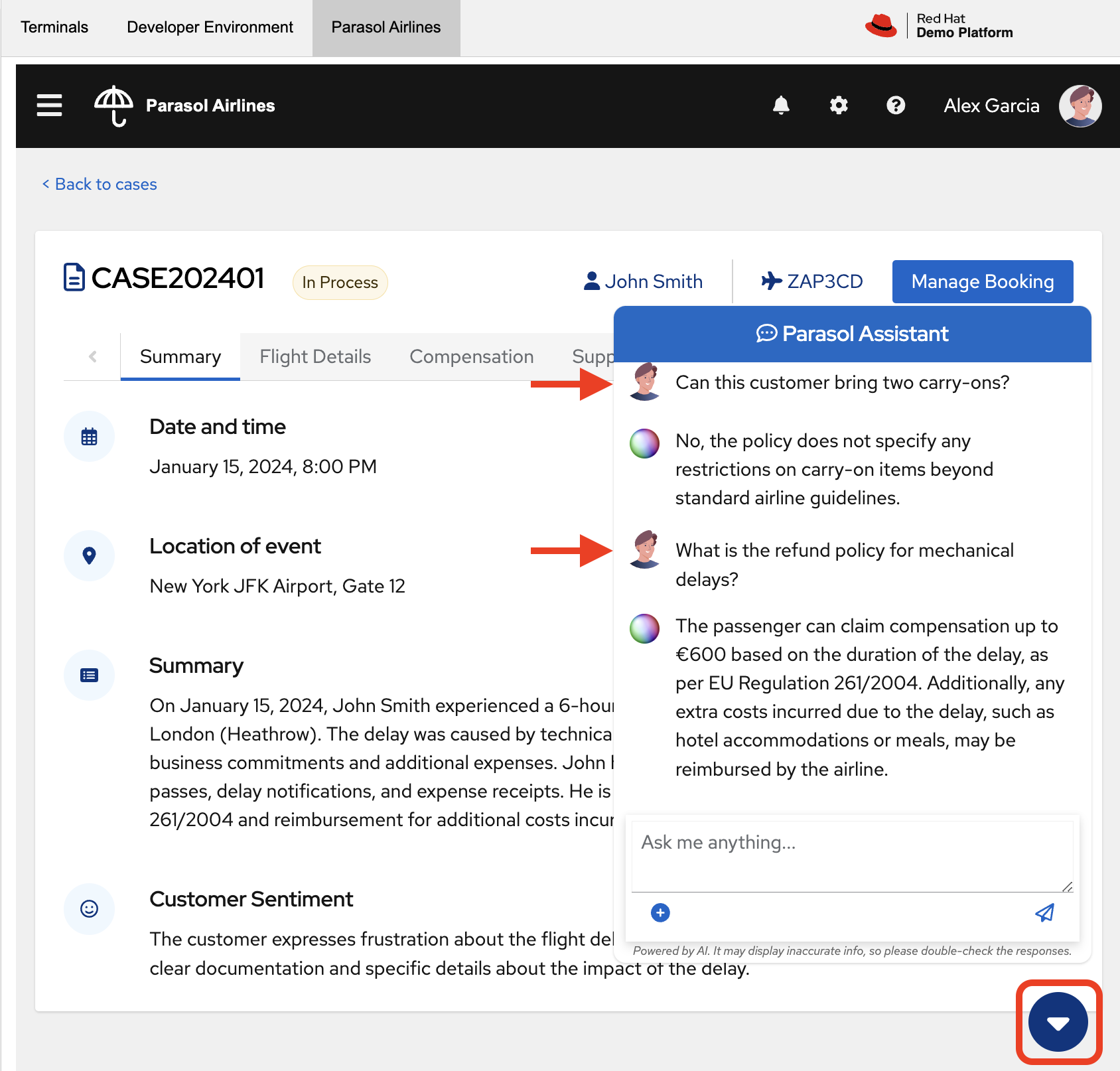
As we extend our AI capabilities, we cam revisit the taxonomy and refine the qna.yaml seed examples used during synthetic data generation. That’s how we iterate and improve, allowing us to adapt our model to new data and requirements. This is a key part of the process, as it allows us to continuously improve our model’s performance and accuracy over time.