Welcome to the workshop!
Thank you for joining this hands‑on lab focused on customizing large language models (LLMs) using InstructLab! InstructLab is an open‑source project licensed under Apache 2.0, leveraging the same Large‑scale Alignment for chatBots (LAB) methodology utilized by Red Hat’s enterprise‑grade AI solutions. Today, we’ll explore how to effectively apply InstructLab’s powerful technology to customize a foundation model to meet the specific needs of a fictional airline, Parasol Airlines. This workshop is designed to be hands‑on and interactive, so you can follow along and apply what you learn in real time.
What you’ll be learning in today’s workshop
Today, you’ll walk through the a sample process of adapting a foundation model to better understand and respond to your unique data—no deep AI/ML background required. By the end of the session, you’ll be able to:
-
Work with local and private large language models (LLMs)
-
Prepare data for model customization, including Markdown and tabular datasets for fine‑tuning
-
Generate high‑quality synthetic data using InstructLab’s automated SDG pipeline
-
Fine‑tune open source foundation models such as Mistral & Granite using LoRA and QLoRA adapters
-
Evaluate your model’s responses and validate their alignment with your enterprise data
-
Serve and use your customized AI model locally on consumer‑grade hardware
-
Integrate your customized model into an application using LangChain4J & Quarkus
What’s your challenge today? You’ll be customizing a foundation model to help out Parasol Airlines with their customer service. Parasol Airlines is a fictional airline that has a lot of customer service inquiries. They want to build a model that can help them answer questions about their policies, flight status, and other customer service inquiries- by integrating their internal data into the model.
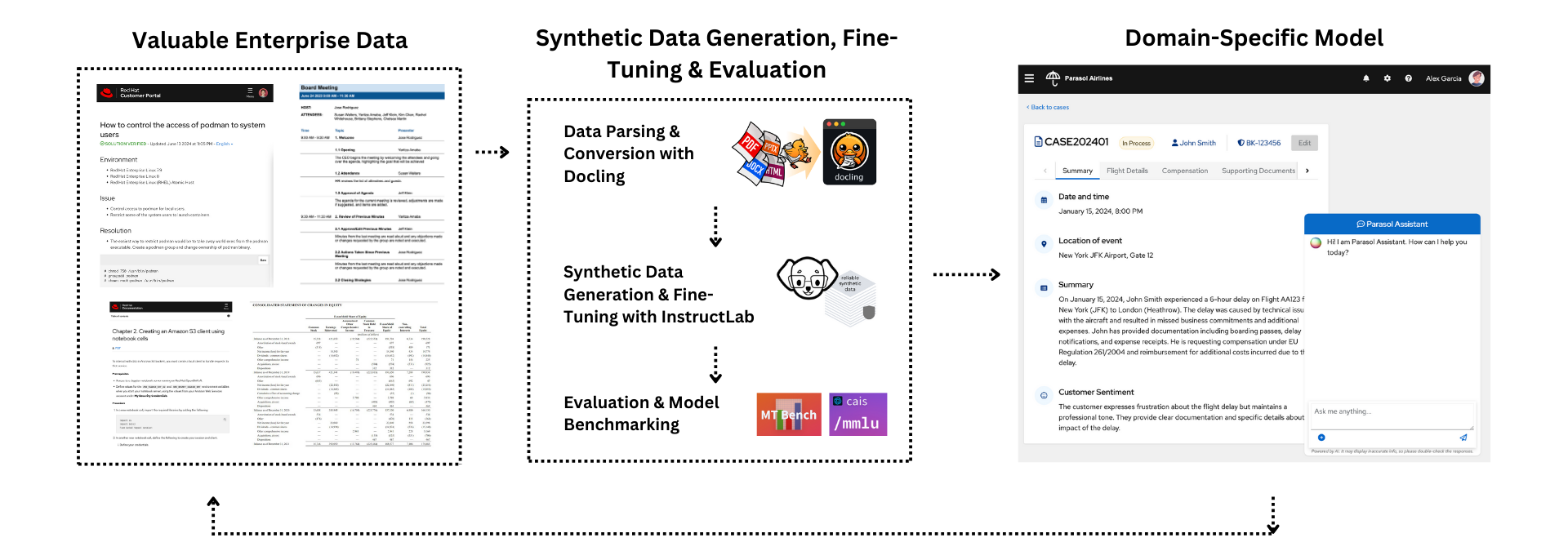
Model Customization with InstructLab and Red Hat Enterprise Linux AI
Today, we’ll work with InstructLab, a community‑driven, open‑source tool designed for local experimentation and customization. InstructLab leverages the original LAB methodology to help you build precise, instruction‑following models through a streamlined synthetic data generation and fine‑tuning workflow. This allows you to customize and align a model to your specific needs, even if you don’t have a lot of data or resources.
InstructLab Features
| Feature | Description & Link |
|---|---|
ilab CLI |
Download, serve, and align models from a unified command-line interface. Installation & usage on your own system at the Getting Started |
Taxonomy-based Contributing Structure |
Define and organize input/output “recipes” in a community-maintained taxonomy to pinpoint capability gaps. Browse or contribute at InstructLab Taxonomy |
Synthetic Data Generation Pipeline |
Generate diverse synthetic data from your taxonomy via a single CLI command. See details in the SDG Repository |
Community-Driven UI |
Optional web interface for skill submission, taxonomy browsing, and run monitoring: InstructLab UI |
Red Hat Enterprise Linux AI extends this with advanced agentic pipelines, tighter integration with hardware layers, and enterprise-grade support- so you can scale prototypes into production with confidence. This workshop will show you how to build and refine models using InstructLab—so you can later scale or transition those workflows into an enterprise environment if needed. Let’s get started!