RAG with Llama Stack
This module walks through an example of using Llama Stack's built-in RAG capabilities.
RAG stands for Retrieval Augmented Generation and is a pattern often used to augment the knowledge of a LLM. Allowing you to bring private data without having to train nor fine-tune a model.
|
Why RAG instead of fine-tuning? Fine-tuning bakes knowledge directly into model weights — it’s expensive, slow, and the data becomes stale. RAG keeps your data external in a searchable store, so updates are instant (re-ingest the document), there’s no GPU-intensive training step, and the model can cite its sources. This makes RAG the preferred approach for enterprise knowledge bases that change frequently. |
Typical RAG implementations involve both an ingestion as well as retrieval process. Some folks refer to these processes as pipelines.
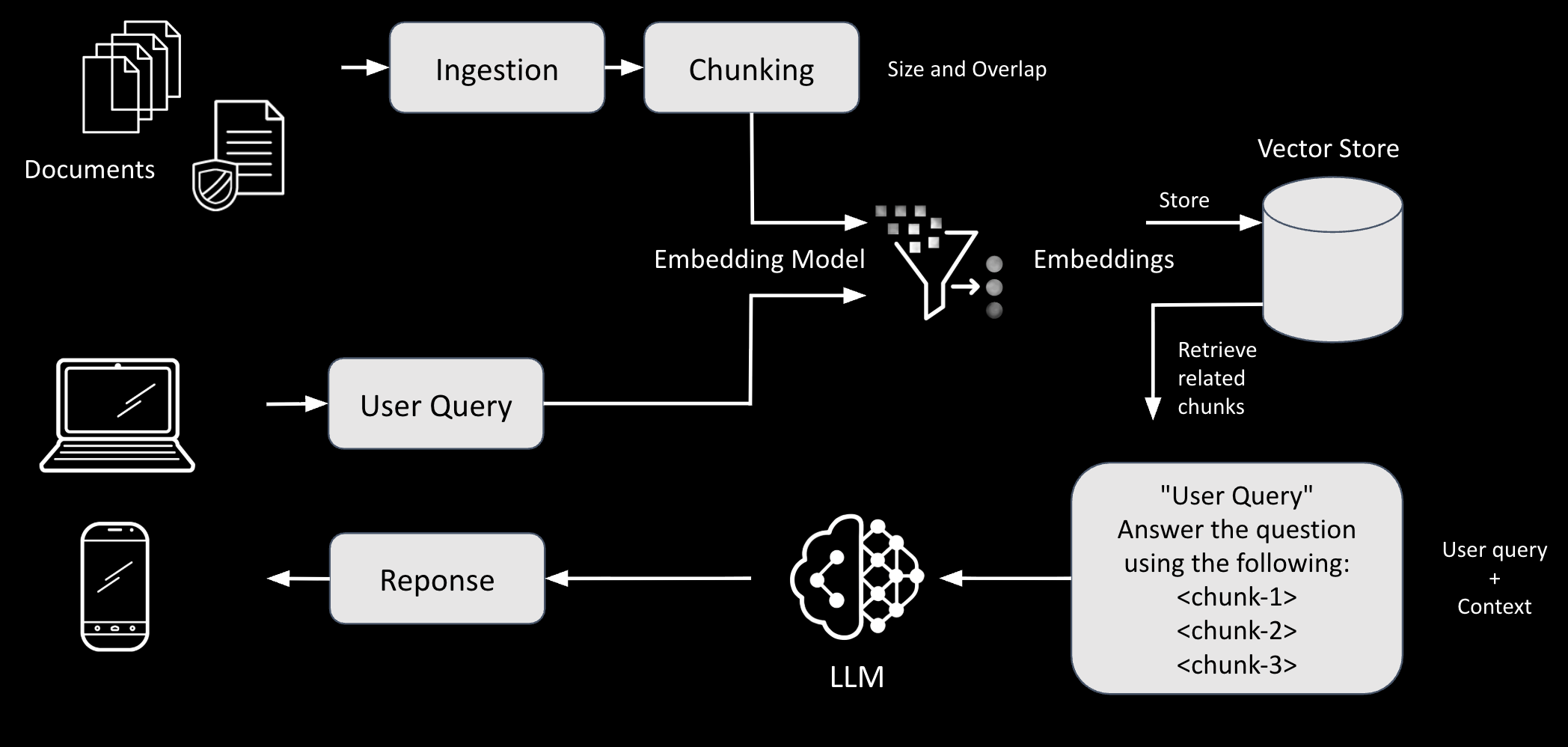
Llama Stack provides native RAG support through its Agent API with the
file_search tool:
-
Vector Store Creation: Documents are uploaded and chunked into smaller pieces
-
Embedding Generation: Each chunk is converted to a vector embedding using an embedding model
-
Vector Search: When a query is made, it's embedded and compared against stored chunks using:
-
Semantic search: Vector similarity (cosine/dot product)
-
Keyword search: BM25 algorithm
-
Hybrid search: Combination of both (configurable weights)
-
-
Retrieval: Top matching chunks are retrieved based on relevance scores
-
Generation: The LLM uses retrieved context to generate answers, citing sources
Make sure you are in the correct directory
cd $HOME/fantaco-redhat-one-2026/
pwd/home/lab-user/fantaco-redhat-one-2026Create a Python virtual environment (venv)
python -m venv .venvSet environment
source .venv/bin/activateChange to the correct sub-directory
cd rag-llama-stackIf you did this correctly then your terminal prompt should look like the following:
((.venv) ) [lab-user: ~/fantaco-redhat-one-2026/rag-llama-stack]$
Install the dependencies
pip install -r requirements.txtFirst see what embedding models are available on your server
python 0_list_embedding_models.pyFetching available models...
Found 1 embedding model(s):
1. sentence-transformers/nomic-ai/nomic-embed-text-v1.5
Provider: sentence-transformers
Resource ID: nomic-ai/nomic-embed-text-v1.5
Dimension: 768.0|
What is an embedding model? Unlike LLMs that generate text, an embedding model converts text into a fixed-size numerical vector (here, 768 dimensions). Texts with similar meaning produce vectors that are close together in this high-dimensional space. This is what makes semantic search possible — your query is embedded and compared against all document chunk embeddings to find the most relevant matches. |
Set env variables to use nomic-embed from HuggingFace.
export EMBEDDING_MODEL=sentence-transformers/nomic-ai/nomic-embed-text-v1.5
export EMBEDDING_DIMENSION=768Then run the ingestion and vector store creation script.
This will take approximately 1 minute.
python 1_create_vector_store.pyLLAMA_STACK_BASE_URL: http://llamastack-distribution-vllm-service:8321
EMBEDDING_MODEL: granite-embedding-125m
EMBEDDING_DIMENSION: 768
--------------------------------------------------------------------------------
Initializing Llama Stack client...
Client initialized successfully
Creating vector store...
✓ Vector store created: vs_5c464ca9-58dc-4f3d-bda9-d7333e4eb2a1
Downloading document...
✓ Downloaded 11727 characters
Uploading document to Llama Stack...
✓ File uploaded: file-7f7cd655e3ff4fd5823098c148176b94
Attaching file to vector store...
Chunking: 100 tokens per chunk, 10 token overlap
✓ File attached to vector store
--------------------------------------------------------------------------------
Checking file processing status...
Waiting 10 seconds for processing to complete...
File ID: file-7f7cd655e3ff4fd5823098c148176b94
Status: completed
✓ File processing completed successfully!
Vector store is ready for querying
Vector store ID: vs_5c464ca9-58dc-4f3d-bda9-d7333e4eb2a1
--------------------------------------------------------------------------------The 1_create_vector_store.py script:
-
Creates a database called "hr-benefits-hybrid" that can search documents using:
-
Keyword search (finding exact words) - 50% weight
-
Semantic search (finding similar meaning) - 50% weight
-
-
Downloads the HR Document
-
Fetches a text file called FantaCoFabulousHRBenefits_clean.txt from GitHub
-
-
Upload the document to Llama Stack Server
-
Chunks the uploaded document
-
Splits the uploaded document into small pieces (100 tokens each, with 10-token overlap)
-
-
Waits to see if the document has been successfully indexed
|
Why chunk and overlap? LLMs have limited context windows and embedding models work best on shorter passages. Chunking splits a large document into small, focused pieces. The 10-token overlap ensures that sentences split across chunk boundaries still have context in both chunks, reducing the chance of losing information at the edges. Why hybrid search? Keyword search (BM25) excels at finding exact terms like product names or policy numbers. Semantic search finds conceptually similar content even when different words are used. The 50/50 weighting combines both strengths. |
You can list the vector stores that Llama Stack is aware of by using curl
curl -sS $LLAMA_STACK_BASE_URL/v1/vector_stores | \
jq -r '.data[] | "\(.name) \(.id)"'hr-benefits-hybrid vs_5c464ca9-58dc-4f3d-bda9-d7333e4eb2a1Or by using Python
python 2_list_available_vector_stores.pyAvailable Vector Stores:
--------------------------------------------------------------------------------
ID: vs_5c464ca9-58dc-4f3d-bda9-d7333e4eb2a1
Name: hr-benefits-hybrid
Created: 1767742908
Files: 1
--------------------------------------------------------------------------------The RAG pattern typically involves two phases - first you ingest and then you augment the retrieval. You have just completed ingestion therefore what is next is retrieval.
Here is an example of the retrieval process via Llama Stack client Agent API and file_search tool
agent = Agent(
client,
model=INFERENCE_MODEL,
instructions="You MUST use the file_search tool to answer ALL \
questions by searching the provided documents.",
tools=[
{
"type": "file_search",
"vector_store_ids": [vector_store.id],
}
],
)|
How does this work? The |
Let’s go execute the retrieval process via Python script.
python 3_test_rag_hr_benefits.pyTo answer the question of What do I receive when I retire?
Using vector store: vs_5c464ca9-58dc-4f3d-bda9-d7333e4eb2a1
Using model: vllm/qwen3-14b
--------------------------------------------------------------------------------
Query: What do I receive when I retire?
--------------------------------------------------------------------------------
🤔
🔧 Executing file_search (server-side)...
🤔
When you retire, you receive a life-sized statue of yourself crafted from
Belgian chocolate (or artisanal vegan carob), a lifetime supply of the
chosen item, and a personal bard to sing your praises at inconvenient
moments, according to the "Midas Touch & Beyond" Retirement Plan described
in the document <|file-c66eed6f65464296bf46a05437f4362a|>.|
What is |
The ultra unique content in the source document is to make it obvious that the responses are NOT in the model's original training data. In a typical enterprise setting you would use documents such as:
-
Policy
-
Standard Operating Procedures
-
Strategy
-
Onboarding guides
-
Meeting minutes
-
Slide decks
| From Terminal 2, you can watch LlamaStack logs to see which APIs are used under the hood by the LlamaStack Client, such as the Response API: |
oc logs -f -l app=llama-stackYou can then continue working in Terminal 1 with the following instructions.
More examples of queries that dive into the unique content, responses truncated a bit for readability. The whimsical content (chocolate statues, office griffins, dolphin language requirements) serves as proof that RAG is working — no model was trained on this data, so correct answers can only come from the retrieved document chunks.
python 6_test_unique_terms.pyUsing vector store: vs_5c464ca9-58dc-4f3d-bda9-d7333e4eb2a1
Query: Tell me about the chocolate statue and personal bard
--------------------------------------------------------------------------------
The chocolate statue is a retirement benefit offered by FantaCo, where
employees receive a life-sized statue of themselves crafted from Belgian
chocolate (or vegan carob) alongside a lifetime supply of the chosen treat
and a personal bard to sing their praises at inconvenient moments. A
pro-tip warns against retiring in August if selecting the chocolate statue,
as it may melt <|file-c66eed6f65464296bf46a05437f4362a|>.
The "personal bard" is part of FantaCo\'s extravagant benefits package,
tasked with singing employees\' praises at unexpected times. This role is
paired with the chocolate statue reward upon retirement, though the bard\'s
services are not limited to retirees and may be tied to other personalized
perks like theme songs composed by in-house minstrels
<|file-c66eed6f65464296bf46a05437f4362a|>.
Query: Tell me about the 401k and astrological alignment
--------------------------------------------------------------------------------
The 401(k) plan described in the provided documents includes a fictional
or satirical element where contributions are multiplied based on the
"current astrological alignment of Jupiter crossed with the number of
positive affirmations uttered in the building that day"
<|file-c66eed6f65464296bf46a05437f4362a|>. This appears to be part of a
whimsical, fictional HR benefits description rather than a real-world
financial mechanism. No further details about astrological alignment
influencing retirement plans are mentioned in the other retrieved
documents.
Query: where might I try a marathon?
--------------------------------------------------------------------------------
You might try training for a marathon on the Great Wall of China, as
mentioned in the document describing FantaCo\'s unconventional benefits
package <|file-c66eed6f65464296bf46a05437f4362a|>. The text suggests this
as an adventurous option for employees with "Adventure Units" to spend on
unique experiences.
Query: What does the office griffin eat?
--------------------------------------------------------------------------------
The office griffin has a strict diet consisting of glitter, existential
dread, and artisanal pickles, as explicitly stated in the document. Feeding
it anything else may cause crankiness
<|file-c66eed6f65464296bf46a05437f4362a|>.
Query: What languages must employees learn?
--------------------------------------------------------------------------------
Employees at FantaCo must learn at least three phrases in Dolphin and one
phrase in Squirrel. This requirement is mentioned as part of the company\'s
whimsical and unconventional workplace policies.
<|file-c66eed6f65464296bf46a05437f4362a|>Once you’re done querying, you can delete the vector stores to clean things up. In production, vector stores are long-lived and updated as documents change — but for this lab, cleaning up avoids conflicts if you re-run the scripts.
python 7_delete_vector_store.pyFetching vector stores...
Found 1 vector store(s):
--------------------------------------------------------------------------------
1. Name: hr-benefits-hybrid
ID: vs_5c464ca9-58dc-4f3d-bda9-d7333e4eb2a1
Created: 1766611605
Delete options:
1. Delete all vector stores
2. Delete by name pattern (e.g., 'hr-benefits-*')
3. Delete specific vector store by number
4. Cancel
Enter choice (1-4):Select 1 and answer yes when prompted
Delete ALL 1 vector store(s)? (yes/no): yes
Deleting 1 vector store(s)...
--------------------------------------------------------------------------------
✓ Deleted: hr-benefits-hybrid (vs_5c464ca9-58dc-4f3d-bda9-d7333e4eb2a1)
Done!